Elasticsearch چیست و چگونه میتوان از آن استفاده کرد
دوشنبه 11 دی 1396اگر از اکثر افراد در مورد کارکرد Elasticsearch بپرسید، جوابهای متفاوتی دریافت خواهید کرد. بسیاری از توسعهدهندگان حرفهای جواب شما را به درستی نخواهند داد. آنها ممکن است طرز استفاده از Elasticsearch را بدانند، اما برایشان سخت باشد تا توضیحی مختصر، دقیق و شفاف بدهند. این مسأله ممکن است، کسانی که قصد یادگیری ES را دارند، ناامید کند و آنها واقعا سردرگم شوند که Elasticsearch چیست؟ چگونه کار میکند؟ چه مزایایی دارد؟

ما در این مقاله پاسخ این سوالات را به صورت جامع و قابل فهم به شما میدهیم. پس همراه ما باشید و از خواندن این مقاله لذت ببرید.
Elasticsearch یک موتور جستجوی open-source، با قابلیت توزیع گسترده و با مقیاسپذیری سریع میباشد. با استفاده از یک API دقیق و گسترده میتواند جستجوهای سریع و فوقالعاده قدرتمند ی را روی دادههای شما انجام دهد.
با Elasticsearch جستجو بسیار آسان میشود. این موتور جستجو پیشفرضهای معقول را ارسال کرده و جستجوهای پیچیده را پنهان میکند. با درک اصول مفاهیم مربوط به این موتور جستجو، میتوانید جستجوهای سریعی انجام دهید.
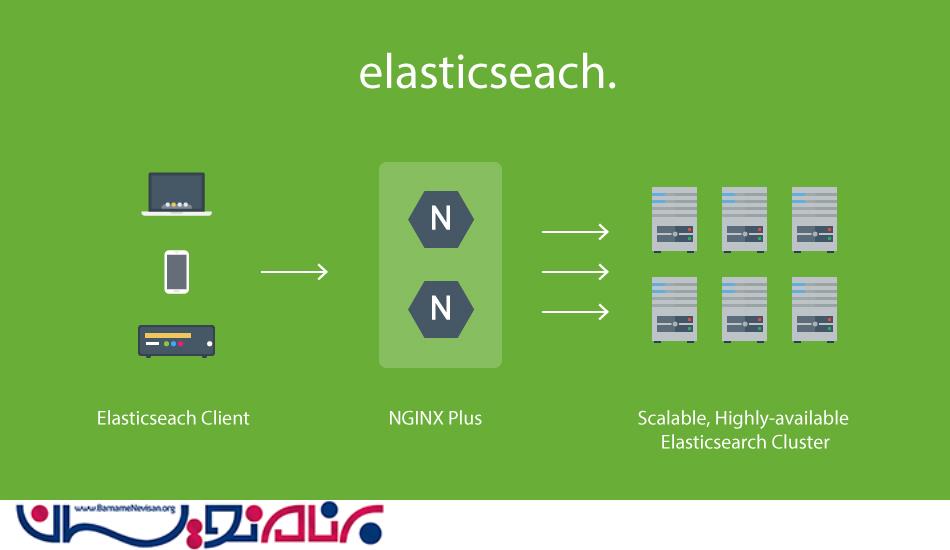
جستجوی سریع و مؤثر در برابر حجم زیادی از دادهها
در حقیقت سیستمهای مدیریت پایگاه داده SQL برای جستجوی تمام متون طراحی نشدهاند و قطعا بر روی دادههای خام ساختیافته که خارج از دیتابیس هستند به خوبی اجرا نمیشوند. روی سختافزاری که پرس وجوها (کوئریها) بیش از 10 ثانیه طول میکشد تا با SQL انجام شود، در Elasticsearch زیر 10 میلیثانیه انجام خواهند شد.
کاربران، کوئری ES را با زبانی ساده، Query DSL، بیان میکنند. یک کوئری یک یا چند هدف را بررسی کرده و به هر یک از عناصر حاصل از نتایج با توجه به نزدیک بودن آنها به کوئری مورد نظر امتیازی میدهد. اپراتورهای پرس وجو شما را قادر میسازد تا کوئریهای ساده یا پیچیده را که اغلب حاصل نتایجی از مجموعه دادههای بزرگ در چند میلیثانیه هستند را بهینهسازی کنید. طراحی Elasticsearch خیلی سادهتر از پایگاه دادههایی است که توسط الگوها، جداول، فیلدها، سطرها و ستونها محدود شدهاند.
ایندکس کردن اسناد برای ریپوزیتوری
در طی عملیات ایندکس کردن، Elasticsearch دادههای خام مثل فایلهای log یا فایلهای پیام را به اسناد داخلی تبدیل کرده و آنها را در یک ساختار داده اساسی شبیه شیء JSON ذخیره میکند. هر سند مجموعه سادهای از کلیدها و مقادیر مربوطه میباشد که کلیدها رشته هستند و مقادیر انواع دادههای مختلفی، مثل رشته، اعداد، تاریخ یا لیست میباشند.
افزودن اسناد به Elasticsearch کار آسانی است و به راحتی به صورت خودکار انجام میشود. به سادگی یک HTTP POST انجام میشود که سند شما را به عنوان شیء ساده JSON ارسال میکند. جستجوها نیز با JSON انجام میشوند. کوئری شما در HTTP GET با بدنه JSON فرستاده میشود. RESTful API عملیات را آسان میکند تا دادهها مستقیما از خط فرمان بازیابی، ارسال و تأیید شوند. حتی اگر آنها با کلاینتی مثل Python یا Ruby در حال توسعه باشند، بسیاری از توسعهدهندگان از ابزار cURL برای اشکالزدایی و توسعه با Elasticsearch استفاده میکنند.
ذخیرهسازی اسناد انحصاری: سریع، با دسترسی مستقیم به دادههای شما
این مهم است که به خاطر داشته باشید که Elasticsearch پایگاه داده رابطهای نیست. بنابراین مفاهیم DBMS معمولا اعمال نخواهند شد. مهمترین مفهومی که شما باید از پایگاه دادههایی که طبق استاندارد خاصی رفتار میکنند جدا کنید، نرمالسازی است. Elasticsearch بومی اجازه دسترسی به سابکوئریها را نمیدهد، بنابراین غیرنرمالسازی دادههای شما ضروری است.
ES معمولا یک بار سند را برای هر ریپوزیتوری که در آن قرار دارد ذخیره میکند. اگرچه این مسأله از دید یک DBMSای که طبق قراردادها رفتار میکند دور از عقل است، اما برای Elasticsearch مطلوب است. جستجوی تمام متون بسیار سریعتر خواهد شد زیرا اسناد در نزدیکی متادیتای مرتبط در ایندکس ذخیره شدهاند. این طراحی به طور عالی تعداد خواندنهای داده را کم میکند و ES با فشردهسازی میزان رشد ایندکس را محدود میکند.
به طور گسترده قابل توزیع و بسیار مقیاسپذیر
Elasticsearch میتواند تا هزاران سرور را پوشش دهد و پتابایتهای داده را با آنها تطبیق نماید. ظرفیت عظیم آن نتیجه معماری توزیعشده و دقیق آن است، و در عین حال کاربر ES میتواند تقریبا از تمام اتوماسیونها و پیچیدگیهای این طراحی توزیعشده بیخبر باشد.
در Elasticsearch این عملیات به صورت اتوماتیک و غیرقابل مشاهده رخ میدهند:
تقسیمبندی اسناد در میان ترتیبی از مقیاسها(shard) یا نگهدارندههای متمایز.
در یک کلاستر چند گرهای،اسناد برای shardهایی که در میان تمام گرهها قرار دارند، توزیع میشوند.
تعادلسازی بین Shardهای تمام گرهها در یک کلاستر تا ایندکس کردن و لود جستجوها به طور مساوی مدیریت شوند.
تکرار و تکثیر هر shard برای ارائه افزونگی داده و failover
درخواست مسیریابی از هر گره در کلاستر برای گرههای خاص حاوی دادههای خاص مورد نیاز شما
افزودن و ادغام گرههای جدید مانند وقتی که می خواهید اندازه کلاستر را افزایش دهید.
توزیع مجدد Shardها برای بازیابی خودکار گرههایی که از دست رفتهاند.
امیدواریم این مقاله برای شما مفید بوده باشد.

- برنامه نویسان
- 10k بازدید
- 4 تشکر