تئوری Hashing و Hash Table ها
پنجشنبه 27 خرداد 1395در این مقاله شما یاد می گیرید که Hash Table چیست، و ما چرا و چه زمانی باید از آن استفاده کنیم. Hash Table ها نوع دیگری از ساختار داده ها هستند که برای جایگذاری المان های داده در یک قالب مشخص به کار می روند . این قالب داده برای خواندن و نوشتن بسیار ساده است.

برای این که بتوانیم Hash Table ها را به صورت کاربردی و عملی یاد بگیریم، باید موارد زیر را در مورد آن ها بررسی کنیم :
Hashing چیست؟
Hash Table ها چه چیزی هستند و ما چرا از آن ها استفاده می کنیم؟
مدیریت برخورد ها (Collision handling) در زمان استفاده از Hash Table ها چگونه انجام می شود؟
Hash Table ها در کجا قرار دارند؟
تفاوت بین Hash Table ها و binary search tree (درخت جستجوی دودویی ) چیست و روش انتخاب آن ها به چه صورت است؟
Hashing چیست؟
Hash Table ها بر پایه مفاهیم Hashing کار می کنند. Hashing فرآیند تبدیل مقادیر از محدوه ی رشته به محدوده ای شامل اعداد صحیح و یا مقادیر index به رشته می باشد که طول مشخص و معینی دارد. عمل Hashing به وسیله ی توابع hash انجام می شود. دو متد متداول برای انجام عملیات hash ، متد folding و متد cyclic shift می باشند، که index مربوط به کلید (key) انتخاب شده را به شما می دهد تا بتوانید از آن ها در Hash Table ها استفاده کنید.
نوع دیگری از متدهای Hash توابع رمزنگاری مانند MD5 و SHA هستند که یک رشته با سایز مشخص در ازای متن وارد شده به شما برمی گردانند و برای هدف های امنیتی مورد استفاده قرار می گیرند. ولی ما در اینجا به بحث درباره ی متدهای رمزنگاری Hash نمی پردازیم.
Hash Table چیست و چرا باید از آن استفاده کنیم؟
Hash Table مجموعه ای از آیتم ها در قالب آرایه است که یک نوع خاصی از index دارند. در یک جدول و یا مجموعه ی معمولی نیز اگر ما Index مربوط به هر آیتم را بدانیم، می توانیم به داده های آن ها سریعاً دسترسی داشته باشیم، زیرا index ها به صورت طبیعی در آرایه ذخیره شده و موجود هستند.
در طول فرآیند hashing یک جدول و یا مجموعه، ابتدا تصمیم می گیریم که کدام ستون و یا فیلد به عنوان کلید اصلی انتخاب شود که این کلید اصلی به عنوان index در Hash Table نیز مورد استفاده قرار خواهد گرفت.
زمانی که ما این کلید را در تابع hash قرار دهیم، این کار به ما یک index می دهد که hash value و یا hash index نامیده می شود. بنابراین ما داده هایمان در یک hash index خاص در جدول جایگذاری می کنیم. هر آیتم داده در مجموعه به صورت مستقیم به چند index دیگر نگاشت شده است، زیرا ما یک کلید در اختیار داریم و این کلید نیز خودش از جنس index است و به راحتی می تواند توسط تابع hash مورد پردازش قرار بگیرد. زمانی که می خواهیم داده ها را از جدول بخوانیم نیز همین مراحل اتفاق می افتد.
بنابراین hash هم در زمان خواندن و هم در زمان نوشتن داده ها برای ما موثر واقع می شود.
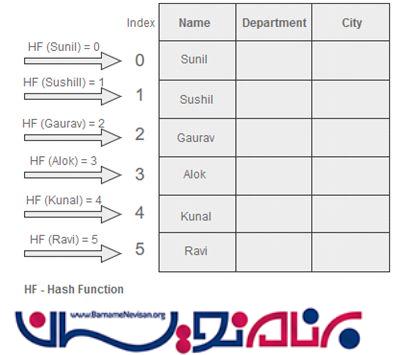
تابع Hash یک نگاشت از فضای ورودی به فضای عدد صحیح است که Index های آرایه را برای ما مشخص می کند.
مشکل: حالا این مشکل وجود دارد که یک hash index مشابه در فرآیند index به چند کلید اختصاص داده شود.
مثال :
hf(k1) = 12 hf(k2) = 12
به عبارت دیگر ممکن است برخورد و یا تضادی اتفاق بیفتد. در این صورت شما چگونه تصمیم می گیرید که کدام مقدار شاخص (data value) را برای کلید مخصوص خودتان ذخیره کنید.
بنابراین در اینجا نیاز به مدیریت برخوردها خواهیم داشت.
Collision handling
(مدیریت برخوردها و تضادها)
استراتژی های مختلفی وجود دارند که این مساله را برای ما حل می کنند. سه استراتژی اصلی عبارتند از :
1- Chaining
2- Linear Probing - Open addressing technique
3- Double Hashing - Open addressing technique
Chaining
اگر بیش از یک مقدار به یک Index مشابه نگاشت شوند، تکنیک Chaining آن بخش از آرایه را با لیست پیوندی جایگزین می کند. در زیر،یک نمایش گرافیکی از آن را می بینید.
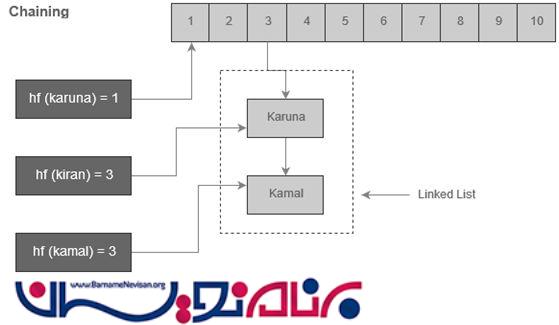
در این شکل، تابع hash (hf) برای دو مقدار، یک index مشابه تولید کرده است. بنابراین این هر دوی این کلیدها به index 3 نگاشت خواهند شد، سپس آن ها با یک لیست پیوندی جایگزین خواهند شد و index 3 به نقطه شروع لیست پیوندی اشاره خواهد کرد.زمانی که ما قصد بازیابی اطلاعات از Hash Table را داریم، دوباره الگوریتم مشابهی اعمال می شود. این تکنیک برای managed languages مانند Hash Table ها و hashmap در Java استفاده می شود.
Open addressing schemes : این تکنیک زمانی استفاده می شود که بخش هایی که در اختیار داریم بیش از مقادیر حقیقی موجود باشند. دو تکنیکی که در این شکل استفاده شده اند عبارتند از :
Linear Probe
در این مورد، اگر تابع hash دو مقدار با hash index مشابه تولید کند ، این تکنیک به دنبال جای خالی دیگری میگردد تا داده بعدی را در آن ذخیره کند.
مثال:
if hf (kiran) = 4 is occupied then it will look for hf (komal) + 1 = 5
این تکنیک این عمل را تا زمانی که یک جای خالی پیدا کند، ادامه می دهد.
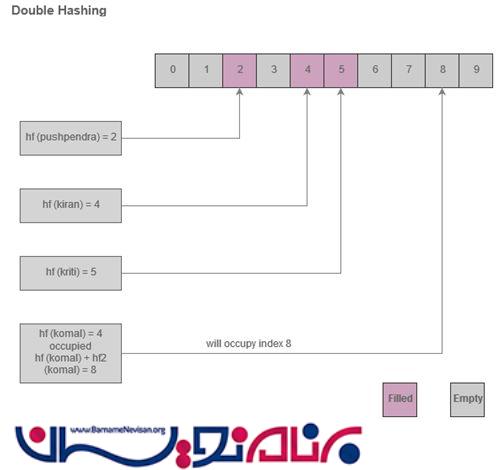
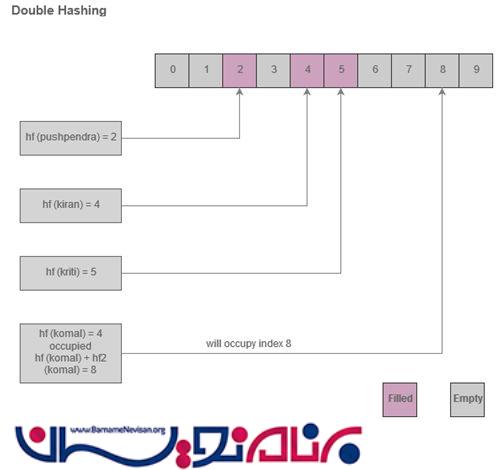
Double Hashing
در این مورد، دو تابع hashing متفاوت استفاده شده اند. اگر تابع اول hf (key) پر شده باشد، تابع دوم hf1 (key) برای ادامه ی کار تابع اول استفاده خواهد شد.
hf (key) = 4 occupied then hf (key) + hf1 (key) = 8 will be used.
در چه مواردی از Hash Table ها استفاده می کنیم؟
ما از Hash Table ها برای ذخیره سازی آرایه ها استفاده می کنیم، تا بتوانیم جفت کلید-مقدار در زبان های برنامه نویسی ای مثل Dictionaries ، Hash Table ها در C# و Hash Table ها و Hashmap در Java استفاده کنیم. با استفاده از این ویژگی، شما می توانید به سرعت یک آیتم را با استفاده از کلید داده شده جستجو کنید بدون این که مجبور باشید تمام مجموعه آرایه موجود در Hash Table را بررسی کنید.
یک فرد همچنین می تواند از Hash Table ها در جداول موقتی در سیستم های پایگاه داده ای مانند SQL Server نیز استفاده کند.
تفاوت بین Hash Table ها و binary search tree (درخت جستجوی دودویی ) چیست و روش انتخاب آن ها به چه صورت است؟
Hash Table خطی و دارای ساختار داده ای نامرتب است در حالی که درخت جستجوی دودویی غیرخطی و مرتب شده است. جستجو و درج در درخت دودویی ، نسبت به Hash Table ها نسبتاً آرام تر انجام می شود. اگر مجموعه ی بزرگ و نامرتبی از داده ها در اختیار دارید، از Hash Table ها استفاده کنید. اگر مجموعه ی کوچک و مرتب شده ای از داده ها دارید، از درخت جستجوی دودویی استفاده کنید که سریع تر نیز عمل می کند.
در موارد دیگر، اگر مجموعه ی کوچکی دارید که قبلا مرتب شده است، نیازی به مصرف حافظه ی اضافی برای مرتب سازی و سپس ذخیره داده های مرتب شده در حافظه نیست. در این حالت از جستجوی دودویی بهره می گیریم.

- C#.net
- 7k بازدید
- 3 تشکر