پیمایش صفحات وب (Web Crawling) با استفاده از #C
شنبه 3 مهر 1395این مقاله پیرامون به دست آوردن داده و اطلاعات از یک صفحه وب خاص است. اما شامل فرآیند رفتن از یک وب سایت یا صفحه وب به سایر وب سایت ها نمی شود. برخی افراد با شنیدن واژه های web crawling (خزیدن در وب ) و web scraping دچار سردرگمی می شوند، اما این دو واژه معنای متفاوتی دارند.
 با استفاده از #C")
web crawling (خزیدن در وب ) فرآیند جستجو و خزیدن صفحات وب (و یا یک شبکه) و بررسی لینک ها و منابع آن صفحه وب است.
نقطه آغازین
می دانیم که web crawling در مورد لینک ها است نه در مورد داده ها. گرفتن داده ها در حوزه ی scraping قرار می گیرد. زمانی که شما بر روی یک صفحه وب، عمل scraping انجام می دهید ، می دانید که در چه زمانی و چه مواردی را می خواهید به دست بیاورید. اگر بخواهید که تمامی وب را index گذاری کنید، از چه نقطه ای شروع خواهید کرد؟ احتمالا از سایت های مشهوری شروع خواهید کرد که می شناسید، و یا با لیستی از DNS server ها شروع می کنید. به هر حال برای شروع، شما به یک نقطه آغازین نیاز خواهید داشت.
عریض یا عمیق
دو روش اصلی برای تصمیم درباره نحوه شروع وجود دارد. شما می توانید به صورت عریض و یا عمیق ، این کار را شروع کنید. (که هر دوی این روش ها مفید و کاربردی هستند) بیایید اینطور در نظر بگیریم که از صفحه اصلی یک سایت شروع می کنیم که دو لینک دارد و هر دوی این لینک ها به لینک های دیگری متصل می شوند. کاری که ما نیاز داریم انجام بدهیم، این است که بهترین روش برای ردیابی این لینک ها را انجام بدهیم.
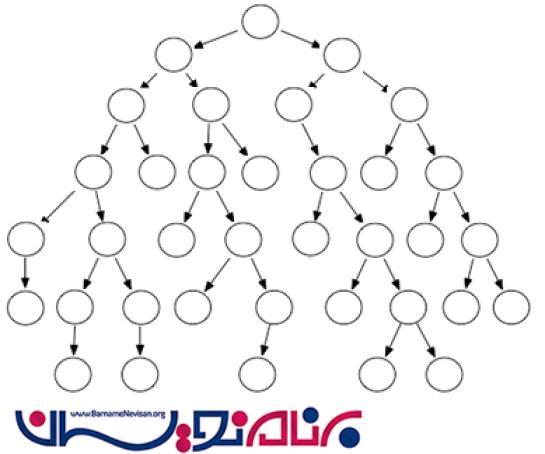
اول سطح (Breadth first)
در این روش، ما از بالاترین گره ای که در صفحه می بینیم شروع می کنیم و لینک هایی که در هر صفحه وجود دارد را بر اساس *breadth/wide*(عرض/سطح) ردیابی می کنیم. ما عمل crawling را بر اساس اولین سطح که به رنگ قرمز است شروع می کنیم. زمانی که این دو لینک کاملا بررسی شدند، ما به سراغ سطح بعدی می رویم که به رنگ سبز است. بعد از اتمام بررسی این سطح، ما به سراغ سطح بعدی می رویم و همینطور تا آخر این کار را ادامه می دهیم.
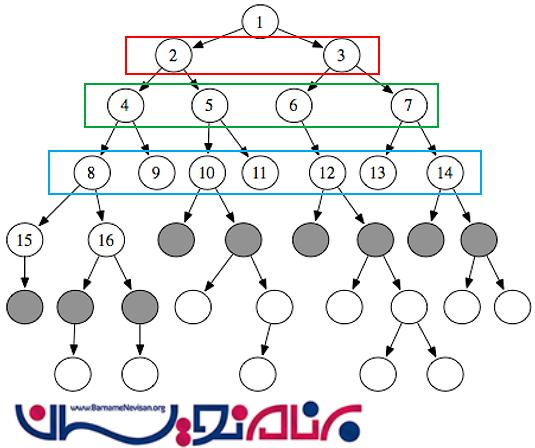
اول عمق (Depth first)
روش اصلی بعدی ، کاوش اول عمق است. این روش به این صورت است که ما لینک ها را به صورت عمقی مورد بررسی قرار می دهیم. در اولین مرحله، ما اولین لینک را در نظر می گیریم (2)، سپس به سراغ لینک بعدی (3) می رویم و این کار را تا رسیدن به اخرین عمق ادامه می دهیم. سپس به سراغ آخرین سطح کناری که دارای گره است می رویم و این کار را تا پیمایش اخرین گره ادامه می دهیم.
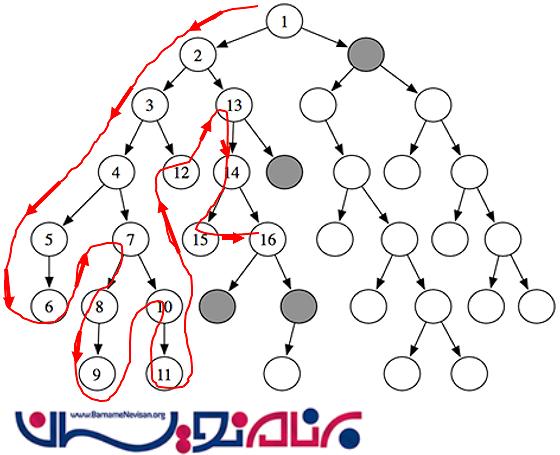
روش های بسیاری برای پیمایش صفحات وب وجود دارد. ما می توانیم این روش ها را به صورت ترکیبی نیز به کار بگیریم. اگر به دیاگرام های بالا توجه کنید، خواهید فهمید که یک روش برای به کارگیری کافی نیست و ما نیاز داریم تا thread ها را به صورت همزمان به کار بگیریم تا بتوانیم فرآیند پیمایش صفحات وب را تکمیل کنیم.
صف های پیمایش
زمانی که شما یک روش را برای پیمایش استفاده می کنید،سوال بعدی که به ذهن می رسد این است که چگونه می خواهید عملیات پردازش را مدیریت کنید. اگر بخواهید تمامی این مسائل را فقط به صورت ذهنی برنامه ریزی و مدیریت کنید، به یک فاجعه منتهی خواهد شد. زیرا در این صورت، اولین راه حل ، استفاده از پشته است که به هیچ وجه بهینه نیست. بهترین روش، ایجاد یک لیست یا صف است، که شما لینک ها را برای انجام عملیات crawling در آن قرار می دهید. سپس هر بار که به لینک جدیدی احتیاج دارید، آن را از صف برمیدارید. همینطور اگر لینک جدیدی نیز پیدا کنید، آن را در صف قرار می دهید و سپس به دنبال سایر لینک ها می گردید. البته استفاده از یک صف FIFO چندان بهینه نیست و بهتر است از یک صف معمولی استفاده شود.
صف های اولویت
یک صف اولویت، یک سیستم صف است که هوش زیادی در پشت آن نهفته است. این صف، لینک ها را می گیرد، و آن ها را به ترتیب از پیش تعیین شده خاصی ، سازمان دهی می کند. ایده صف اولویت، این است که اطلاعات بر اساس یک اولویت خاص در آن قرار می گیرند و سپس بر اساس همان اولویت نیز از آن استخراج می شوند. شما می توانید اولویت را خودتان مطابق با هر فاکتوری که دوست دارید، تنظیم کنید. هدف صف اولویت این است که به شما اجازه ی فیلتر کردن و برداشتن آیتم ها را از صف بر اساس یک ترتیب خاصی بدهد. ممکن است ما تصمیم بگیریم که لینک های مربوط به فایل های PDF ، اولویت بیشتری نسبت به فایل های DOCX داشته باشند. همچنین ممکن است لینک های سطح بالا از اهمیت بیشتری نسبت به لینک های سطح پایین برخوردار باشند.
اولویت های مربوط به لینک ها
Domain_1.com بالا
Domain_2.com بالا
SubDomain.Domain_2.com پایین
Domain_3.com بالا
SubDomain2.Domain_1.com پایین
ممکن است لینک ها بر اساس نیاز و شیوه پیاده سازی ما، حاوی اطلاعات بیشتری نیز باشند.
سیاست ها و قوانین
در تعریف این که چه لینک هایی را باید پیمایش کنیم، و بر اساس چه اولویت هایی ، این کار باید صورت بگیرد، ما معمولا به لیستی از سیاست ها و قوانین مراجعه می کنیم. به عنوان مثال :
-آیا این یک لینک/وب سایت است که ما می خواهیم به آن برویم؟
-آیا ما قبلا این لینک را بازدید کرده ایم و اگر جواب مثبت است، این بازدید در چه تاریخی بوده است ؟
-آیا این لینک در دسته لینک هایی که ما قصد پیمایش آن ها را داریم، قرار دارد یا نه؟
-ما بر چه اساسی لینک های مورد نیازمان برای پیمایش را انتخاب می کنیم؟ بر اساس URL، صفحه ای که از آن به این لینک ، هدایت شده ایم و یا بر اساس محتویات و متن های داخلی لینک؟
-آیا ما به دنبال نوع خاصی از لینک ها یا مطالب هستیم؟
-زمانی که URL re-direct اتفاق بیفتد، چه کاری می خواهیم انجام بدهیم؟
مدیریت State
بر اساس این که سایتی که در حال پیمایش آن هستید، چگونه پیکربندی شده است ممکن است به مدیریت State نیاز داشته باشید و یا این که اصلا به این مورد نیازی نداشته باشید. در اینجا، State به معنای توانایی و یا قابلیت حرکت از یک صفحه به صفحه ای دیگر بر اساس پردازش اطلاعاتی است که سرور آن ها را تولید کرده و سپس انتقال این اطلاعات به شما که در نقش یک کاربر هستید و سپس دریافت پاسخ از جانب سرور برای حرکت از یک صفحه به صفحه ای دیگر است.
این، یک مثال از ASP.net 'ViewState' است.
یک کاوشگر وب حرفه ای باشید.
Robot ها
وب سرور ها برای این که به شما اجازه/ عدم اجازه برای پیمایش یک وب سایت که تحت مدیریت آن ها است را بدهند، یک متد دارند. متدی که وب سرور برای اطلاع رسانی به کاربر از آن استفاده می کند، خیلی ساده است. در بخش اصلی یک domain/website، یک فایل به نام 'robots.txt' اضافه می شود و در آن قوانین مورد نظر اضافه می شود.
در زیر برخی از این مثال ها آورده شده است.
محتویات این فایل robots.txt مشخص می کند که این وب سایت اجازه پیمایش را به کاوشگرها می دهد .
User-agent: * Disallow:
دستور زیر عدم اجازه برای پیمایش را نمایش می دهد.
User-agent: * Disallow: /
دستور زیر به این معنی است که شما می توانید به همه قسمت ها بجز پوشه ی photos دسترسی داشته باشید.
User-agent: * Disallow: /photos
بنابراین برای این که با سرور بتوانیم به بهترین شکل،ر ابطه برقرار کنیم ، نخستین کاری که باید انجام بدهیم، جستجو برای یافتن یک فایل robots.txt است در دامنه مورد نظرمان است. (MyDomain.com/robots.txt)
اگر این فایل را پیدا کردید باید از قوانین نوشته شده در آن پیروی کنید و اگر این فایل را پیدا نکردید، می توانید خزیدن و پیمایش وب را در همه صفحات انجام بدهید.
در زیر نمونه ای از فایل Robots.txt که مربوط به سایت Amazon.co.uk است، برای شما آورده شده است.
User-agent: * Disallow: /exec/obidos/account-access-login Disallow: /exec/obidos/change-style Disallow: /exec/obidos/flex-sign-in Disallow: /exec/obidos/handle-buy-box Disallow: /exec/obidos/tg/cm/member/ Disallow: /exec/obidos/refer-a-friend-login Disallow: /exec/obidos/subst/partners/friends/access.html Disallow: /exec/obidos/subst/marketplace/sell-your-stuff.html Disallow: /exec/obidos/subst/marketplace/sell-your-collection.html Disallow: /gp/cart Disallow: /gp/customer-media/upload Allow: /wishlist/universal* Allow: /wishlist/vendor-button* Allow: /wishlist/get-button* Disallow: /gp/wishlist/ Allow: /gp/wishlist/universal User-agent: EtaoSpider Disallow: / # Sitemap files Sitemap: http://www.amazon.co.uk/sitemap-manual-index.xml Sitemap: http://www.amazon.co.uk/sitemaps.f3053414d236e84.SitemapIndex_0.xml.g
صبور باشید و آهسته به پیش بروید
بارها رخ داده است که در هنگام پیمایش و حرکت در صفحات یک وب سایت خاص، سرور قادر به پاسخگویی و مدیریت درخواست ها نباشد و سایت به صورت ناگهانی دچار اختلال و خطا بشود. در این گونه موارد که به ندرت اتفاق می افتند، چاره ای جر این نیست که با شرکت میزبانی دهنده وب سایت تماس گرفته و مشکل را با آن ها در میان بگذاریم.
همچنین برای جلوگیری از این گونه اتفاقات، شما می توانید پیش از انجام عملیات مورد نظرتان، ابتدا "terms and conditions'" مربوط به هر وب سایت را مطالعه کنید. در اینجا ذکر این نکته لازم و ضروری است که هنگامی که تصمیم می گیرید یک سایت را مورد مطالعه و پیمایش قرار بدهید ، ابتدا به این مورد توجه کنید که قوانین خاصی برای پیروی وجود دارد یا خیر. در صورتی که هیچ گونه قانونی وجود نداشت، شما برای انجام هر کاری از لحاظ قانونی مجوز دارید ولی در صورتی که با قوانین و یا شروط خاصی در وب سایت رو به رو شدید، باید از آن ها پیروی کنید.
پیمایش های خودتان را به صورت برنامه ریزی شده انجام دهید.
شما باید این نکته را به یاد داشته باشید که سرور ها در ساعات خاصی از روز ، ترافیک بیشتری را پذیرا هستند. این ساعات را می توانید با توجه به زمینه ی فعالیت سایت تخمین بزنید. بنابراین زمانی که در حال برنامه ریزی برای انجام عملیات پیمایش بر روی یک سایت هستید، زمان را نیز در نظر بگیرید.
مواردی که می توانند موجب بروز خطا شوند
به صورت کلی، زمانی که ما برای لینک های یک وب سایت، عملیات پیمایش انجام می دهیم، موثر ترین راه استفاده از مجموعه ای از Pool و یا threadها است. زمانی که از thread ها استفاده می کنیم، باید مطمئن باشیم که آن ها به یک روش ایمن در حال اجرا شدن هستند. و اگر یکی از موارد از این نکته پیروی نمی کند، بتوانیم آن را بدون مشکل، مدیریت کنیم. در زیر برخی از مواردی که ممکن است باعث مشکل شوند، آورده شده اند:
-کدهای پاسخ سرور ، کدهایی هستند که از سمت سرور به سمت کاربر فرستاده می شوند تا موقعیت کاربر تشخیص داده شود. این کدها شامل پیام های موفقیت/ اطلاعات مانند “OK” و همچنین پیام های redirect می شوند. خطا های 400 از نوع خطاهای کاربر هستند (مانند خطای 404 ) و خطاهای 500 از نوع خطاهای تولید شده توسط سرور هستند. (مانند خطای 500)
-Timeout : اگر فراخوانی سرور با Timeout مواجه شود به این معنی است که سرور پاسخ نمی دهد. مدیریت این خطا چگونه است؟
-تلاش مجدد؟
-اتمام درخواست؟
-گزارش این خطا؟
-لینک های بازگشتی/حلقه ای/حلقه ها : ما نیاز داریم تا مطمئن شویم درون حلقه های بی نهایت و یا درخواست هایی که به صورت مرتب تکرار می شوند،قرار نمیگیریم.
-سرعت اینترنت: چه اتفاقی می افتد اگر ارتباط شما با اینترنت قطع شود و یا سرور زمان زیادی را برای پاسخ به درخواست شما در نظر بگیرد؟
-شما thread های بسیار زیادی را باز کرده اید- چه اتفاقی می افتد اگر فرد پیمایش کننده سایت، بر روی سروری که میزبانی سایت را بر عهده دارد، تاثیر بگذارد؟ آیا برای کنترل این موضوع، نیاز به بررسی میزان مصرف حافظه خواهید داشت؟
-میزان حداکثر thread ها- برای استفاده از thread ها در پیمایش های همزمان، محدودیت وجود دارد و شما باید این محدودیت را در نظر بگیرید.
لزوم مدیریت زمان در عملیات پیمایش
حقیقتی که در دنیای امروز وجود دارد این است که زمانی که یک کتاب (به عنوان مثال یک کتاب مرجع) در حال نوشته شدن است ، مطالب آن منقضی شده اند. دلیل این موضوع این است که اغلب امور در دنیای امروز پایدار نیستند و دائما در حال تغییر هستند. این موضوع از دید پیمایش وب، یک امر مهم تلقی می شود. بنابراین شما زمانی که به پیمایش یک وب سایت می پردازید ، باید زمان مناسبی را برای شروع و همچنین پایان عملیات در نظر بگیرید.

نحوه مدیریت/ بهینه سازی
مطلب مهم بعدی این است که همه مسائلی که تا کنون آموختیم را در قالب یک معماری پیاده سازی و جمع بندی کنیم. ما برای این کار می توانیم از فریم ورک های موجود استفاده کنیم یا حتی در صورت لزوم یک فریم ورک جدید ایجاد کنیم. مواردی که در این زمینه بسیار موفق و قدرتمند هستند، مانند Facebook, Microsoft و Google می توانند به صورت مستقیم و غیرمستقیم به ما مطالب زیادی بیاموزند. دو تا از پروژه هایی که ما آن ها را در این مقاله پیشنهاد می کنیم Hadoop و MongoDB هستند. هر دوی این تکنولوژی ها برای حل مشکلات مربوط به مقیاس طراحی شده اند و هر دو میزان بسیار زیادی از داده ها را می توانند مدیریت کنند.
چه کسی مسئول اصلی است؟ Guvnor
در بسیاری از سیستم های مکانیکی ، شما با Governor مواجه خواهید شد. در تصویر جالب زیر ، پیاده سازی سخت افزاری از مجموعه ای از قوانین را می بینید که با توجه به ورودی، نحوه تنظیم و مدیریت فعالیت سیستم ،کشیده شده است. در سال های قبل در زبان انگلیسی (و حتی در زمان های اخیر) یک مدیر با لقب 'Guv'ner' مورد خطاب قرار می گرفت.
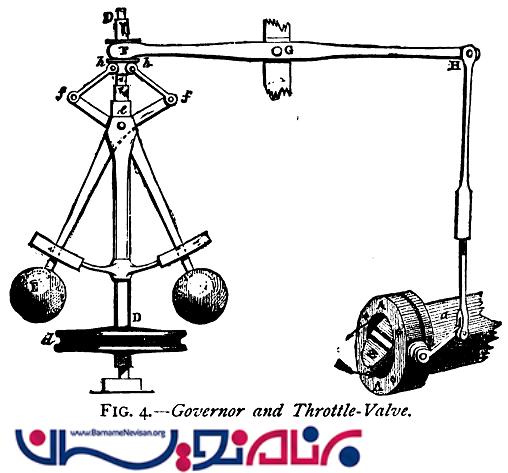
یکی از بخش های متداولی که در سیستم هایی با مقیاس های گسترده با آن مواجه می شویم، یک مدیر مرکزی است. در اغلب موارد، این مدیر در قالب یک کنترل کننده ترافیک در شبکه ای شامل گره های پراکنده ایفای نقش می کند. در مورد معماری پیمایشگر ما ، این مدیر می تواند به عنوان پخش کننده وظایف به گره ها، دریافت کننده نتایج پس از پیمایش و همچنین کنترلگر نحوه فعالیت و راندمان سیستم در نظر گرفته شود. با توجه به این که ما در معماری خودمان، Guvnor را به عنوان یک مدیر سطح بالا در نظر گرفتیم، برای کنترل موثر مواردی مانند عملکرد، راندمان و مقیاس ، خود Guvnor نیز می تواند مجموعه ای از موتور های کوچک تر باشد که در قالب یک سیستم یکپارچه مشغول به کار هستند.
گره های فعال پراکنده شده
برخی از مطالبی که ما از Hadoop فراگرفتیم عبارتند از map/reduce و مدیریت کارهای کوچک به وسیله ی 1..n ماشین پراکنده برای "به اشتراک گذاری و تقسیم فشار کاری " است. پروژه های در مقیاس بزرگ، مانند Hadoop همچنین به ما یاد دادند که در اغلب موقعیت ها، یک معماری مناسب می تواند به میزان زیادی عملکرد کار را بهبود ببخشد. در مورد معماری یک پیمایشگر، ما می توانیم گره های فعال سبکی را طراحی کنیم که فقط یک پوسته ی اجرایی قابل اتصال باشند. هدف این کار عبارت است از :
-شروع (در thread pool)
-اتصال با Guvnor برای دریافت دستورالعمل ها
-دانلود و نصب یک پلاگین سبک
-اجرای متد "execute " در پلاگین پیش فرض
-تکمیل عمل پیمایش
-گزارش نتایج به Guvnor
-قطع عملیات یا بازگشت به Guvnor برای انجام عملیات بعدی
با استفاده از گره های فعالی که پراکنده تنظیم شده اند، ما می توانیم به صورت موثری مدیریت را بهینه تر انجام بدهیم .
صف های اولویت مدیریت شده
ما در ابتدای مقاله در مورد صف های اولویت صحبت کردیم. این صف چندان سنگین نیست و برای پایگاه داده های مبتنی بر دیکشنری بسیار مناسب است (مانند Redis یا Riak) هر دو ی این سیستم ها می توانند به آسانی به عنوان یک پایگاه داده ی FIFO که دارای اولویت است، به کار گرفته شوند.

مزیت استفاده از سیستم های موجود مانند این دو سیستم این است که آن ها باعث صرفه جویی در زمان توسعه و برنامه نویسی ما می شوند. همچنین آن ها قبلا به صورت گسترده مورد تست و ارزیابی قرار گرفته اند و امتحان خود را پس داده اند. اما به معنی این نیست که ما فقط باید از این گونه سیستم ها استفاده بگیریم. راه حل های زیادی در این باره وجود دارند، تنها نکته ای که در اینجا اهمیت دارد این است که ما با توجه به هدفی که دنبال می کنیم، بهترین و بهینه ترین راه را انتخاب کنیم.
اتصال گره ها
زمانی که از یک پایگاه داده مبتنی بر دیکشنری استفاده می کنیم، ممکن است از تکنولوژی های دیگری نیز کمک بگیریم تا داده ها و همچنین روابط بین لینک ها را برای ما مدیریت و نگهداری کنند. به یاد داشته باشید که در زمان پیمایش یک وب سایت ما علاوه بر این که لازم داریم بدانیم مقصد بعدی ما برای پیمایش کجاست، همچنین نیاز داریم بدانیم که مقصد قبلی ما کجا بوده است و همچنین رابطه بین این دو مورد ، به چه صورتی است . به همین خاطر بهتر از ترکیب چندین تکنولوژی برای این کار بهره بگیرید و خودتان را به استفاده از یک تکنولوژی خاص محدود نکنید.

برای این گونه موارد ممکن است به فکر استفاده از SQL Server یا MongoDB بیفتیم که راه حل مناسبی به نظر می رسند. ما همچنین استفاده از Neo4J که بسیار قدرتمند است را به شما توصیه می کنیم.
تکنولوژی هایی که باید به فکر استفاده از آن ها باشید
زبان ها و فریم ورک ها
به صورت کلی، برای یک کار کوچک که باید در زمان کوتاهی انجام شود، به شما توصیه می کنیم که فقط از دانشی که دارید استفاده کنید. اگر به اندازه کافی زمان دارید و توانایی یادگیری مسائل جدید را نیز دارید، به شما توصیه می کنیم که به سراغ یادگیری مطالب جدید بروید. زیبایی اکوسیستم .net این است که شما می توانید تقریبا از زبان های متفاوت و گسترده ای مانند VB.net, C# و F#در کنار هم استفاده کنید. به این صورت که شما می توانید یک کد را که در یک کلاس دیگر و با یک زبان دیگر نوشته شده است را با یک زبان دیگر فراخوانی و استفاده کنید. به ویژه زمانی که نیاز دارید تا یک زبان را به نوع دیگری از زبان تبدیل کنید، این مورد می تواند به شما کمک زیادی کند.
C# زبان بسیار قدرتمندی است و برای پیمایش صفحات وب و استخراج اطلاعات بسیار مفید است . مزایای این زبان نسبت به سایر روش ها بسیار زیاد است و ما استفاده از این زبان را به شدت به شما توصیه می کنیم.
یک فریم ورک پیمایش جالب وجود دارد که اغلب مواردی که ما در بالا به آن ها اشاره کردیم را در بر می گیرد. نام این فریم ورک، ABo است که بسیار قدرتمند و توانا است.
پلتفرم ها
حتی اگر شما در یک جزیره دور افتاده در حال زندگی باشید، محال است از تغییرات بی شماری که این روز ها در شرکت Microsoft اتفاق می افتد، بی خبر بمانید. کدهای زیادی توسط این شرکت به شکل open-source در آمده اند و بسیاری دیگر نیز چندسکویی (multi-platform) شده اند. این تغییرات، تغییرات بزرگ و وسیعی محسوب می شوند. البته برای ما توسعه دهندگان بسیار مطلوب و خوشایند است و ما این تغییرات را با آغوش باز پذیرا هستیم. می دانیم که اکثر پلتفرم های شرکت Microsoft بر روی بستر دسکتاپ فعالیت دارند، البته این موضوع به معنی یک نقص برای این محصولات محسوب نمی شود. ما فقط داریم به این نکته اشاره می کنیم که شاید در دنیای امروز بسیاری از برنامه ها برای اجرا شدن نیازی به یک سیستم عامل مبتنی بر گرافیک نداشته باشند. اگر اینطور باشد ، اولین گزینه برای شما MONO خواهد بود که بر روی سیستم های مبتنی بر UNIX اجرا می شود. انتخاب بعدی نیز می تواند 'NANO' باشد که می تواند برای سیستم های بزرگ پیمایش وب نیز انتخاب خوبی محسوب شود.
امیدواریم از خواندن این مقاله لذت برده باشید. آموزش سی شارپ

- C#.net
- 7k بازدید
- 8 تشکر