خزیدن در وب با استفاده از #C
پنجشنبه 13 آبان 1395در این مقاله می خواهیم با مفاهیم پایه ای مربوط به خزیدن در یک وب سایت (Web Scraping) آشنا شویم. همچنین روش ها و ابزار مربوط به این کار را فرا می گیریم و آن ها را در برنامه هایی به صورت جداگانه پیاده سازی می کنیم.

خزیدن در وب با استفاده از C#
وقتی که ما با منابع داده ای گوناگونی سرو کار داریم، عموما به داده های ساختار یافته یا نیمه ساختار یافته ای که در SQL ، Web-service ها و یا CSV ها نمایش داده می شود، توجه می کنیم. اگر چه حجم داده ای که در واقع در دنیای بیرون وجود دارد، بسیار زیاد و گسترده است و بخش کوچکی از آن ها در قالب وب سایت ها به ما نمایش داده می شود. مشکلی که در این زمینه وجود دارد این است که ما نمی توانیم به نتیجه دقیق و مشخصی با استفاده از داده های درون وب سایت ها برسیم. زیرا داده ها در این حالت، درون ساختار پیچیده ای از css و html قرار دارند. وظیفه ی web-scraping (خزیدن در وب ) این است که داده ها را از وب سایت ها با استفاده از اتوماسیون کد بگیرد و در فرمتی نشان بدهد که ما بتوانیم با آن ها کار کنیم.

خزیدن در وب به دلایل مختلفی انجام می گیرد اما مهم ترین دلیل، این است که راه ساده تری برای به دست آوردن داده ها وجود ندارد. روش خزیدن در وب اصولا توسط شرکت هایی انجام می گیرد که با مشتری ها و قیمت ها به میزان زیادی سر و کار دارند.
وب سایت ها به روش های مختلفی ساخته شده اند، برخی از آن ها بسیار ساده هستند و برخی دیگر، بسیار پیشرفته و پیچیده هستند. خزیدن در وب نیز مانند سایر موارد، کمی نیاز به مهارت و کمی هم یادگیری دارد. ما در این مقاله ، مبانی مربوط به خزیدن در وب را مورد پردازش و بررسی قرار می دهیم. بنابراین این مقاله برای افرادی مفید است که تا به حال، سابقه کار در زمینه ی خزیدن در وب نداشته اند اما به هر حال مطالب مفیدی که بیان می شود، می تواند برای همه مفید باشد.
اگر شما بخواهید لیستی از کشورهای اتحادیه اروپا در اختیار داشته باشید و پایگاه داده ای از همه ی کشور ها در اختیار داشته باشید، به روش زیر عمل خواهیم کرد:
'select CountryName from CountryList where Region = "EU"
راه دیگر این است که به وب سایتی برویم که لیست کشورها را دارد، کشورهای مربوط به اتحادیه اروپا را پیدا کنیم و لیست را از آن جا بگیریم. دقیقا این کار، همان مفهوم خزیدن در سایت است.
فرآیند خزیدن در وب سایت (Web scraping) به ما کمک می کند تا تکه کد زیر را به کد بعدی تبدیل کنیم:
<tbody> <tr> <td>AJSON </td><td> <a href="/home/detail/1"> view </a> </td></tr><tr> <td>Fred </td><td> <a href="/home/detail/2"> view </a> </td></tr><tr> <td>Mary </td><td> <a href="/home/detail/3"> view </a> </td></tr><tr> <td>Mahabir </td><td> <a href="/home/detail/4"> view </a> </td></tr><tr> <td>Rajeet </td><td> <a href="/home/detail/5"> view </a> </td></tr><tr> <td>Philippe </td><td> <a href="/home/detail/6"> view </a> </td></tr><tr> <td>Anna </td><td> <a href="/home/detail/7"> view </a> </td></tr><tr> <td>Paulette </td><td> <a href="/home/detail/8"> view </a> </td></tr><tr> <td>Jean </td><td> <a href="/home/detail/9"> view </a> </td></tr><tr> <td>Zakary </td><td> <a href="/home/detail/10"> view </a> </td></tr><tr> <td>Edmund </td><td> <a href="/home/detail/11"> view </a> </td></tr><tr> <td>Oliver </td><td> <a href="/home/detail/12"> view </a> </td></tr><tr> <td>Sigfreid </td><td> <a href="/home/detail/13"> view </a> </td></tr></tbody>
تبدیل به :
AJSON
Fred
Mary
Mahabir
Rajeet
Philippe
etc…
حالا قبل از این که از این مسائل جلوتر برویم، باید به این نکته اشاره کنیم که شما فقط زمانی می توانید داده ها را کاوش کنید که اجازه این کار را داشته باشید و یا دسترسی به داده ها آزاد باشد. قبل از این که به کاوش داده ها بپردازید، قوانین و شرایط آن را در وب سایت مطالعه کنید و با آگاهی از قوانین، به این کار بپردازید.
زمانی که به طراحی یک وب سایت می پردازید، شما کدهای مورد نیاز را دارید، منابعی که به آن ها متصل می شوید را می دانید و از چگونگی ارتباط و کارکرد بخش ها نیز اطلاع دارید. اما زمانی که به کاوش داده ها (خزیدن ) در یک سایت می پردازید، اطلاعات کمی در اختیار دارید و بنابراین باید مراحل زیر را انجام دهید:
1-کشف/ کاوش
2-نگاشت فرآیندها
3-مهندسی معکوس
4- تبدیل Html/ Data
5-خودکار سازی Script ها
یک بار که این عمل را انجام بدهید، این کار را به عنوان یک مهارت فرا خواهید گرفت و برای شما بسیار کاربردی و مفید خواهد بود.
ابزار خزیدن در وب
ابزار های متعددی وجود دارند که می توانند برای خزیدن در وب مورد استفاده قرار بگیرند. ما در اینجا از دو ابزار استفاده می کنیم. یکی "Fiddler" است که برای انجام عمل مهندسی معکوس بر روی سایت ها/ صفحه ها مورد استفاده قرار می گیرد و دیگری کتابخانه ی "Scrapy sharp" است که open source هم هست.
Scrapy Sharp
Scrapy Sharp یک فریم ورک open source است که شامل ترکیبی از یک کاربر وب است که می تواند یک مرورگر را شبیه سازی کند و همچنین یک افزونه ی HtmlAgilityPack دارد که می تواند المان ها را با استفاده از css selector انتخاب کند. Scrapysharp به میزان زیادی سرعت و کارایی برنامه را افزایش می دهد. با شبیه سازی یک مرورگر ، کنترل cookie ها و برخی دیگر از عملکرد ها نیز امکان پذیر می شود. قدرت ScrapySharp فقط در سیستم شبیه ساز مرورگر آن نیست، بلکه در تعاملی است که با HTMLAgilitypack پیدا می کند. HTMLAgilitypack به ما اجازه می دهد تا در فرم های html به داده ها به شکل بسیار آسانی دسترسی پیدا کنیم.
Fiddler
Fiddler یک proxy توسعه است که بر روی ماشین محلی قرار می گیرد و تمامی درخواست های مرورگر شما را ترجمه و بررسی می کند و آن ها را برای ارزیابی و تحلیل در اختیار شما قرار می دهد.
Fiddler نه تنها در انجام عملیات مهندسی معکوس به شما کمک می کند، بلکه در عملیاتی مانند web-session manipulation, security testing, performance testing, و traffic recording نیز بسیار مفید است . Fiddler یک ابزار بسیار قدرتمند است که در زمان شما بسیار صرفه جویی می کند. برای دانلود Fiddler ، می توانید اینجا کلیک نمایید . بیایید اندکی درباره ی مسائل پایه ای Fiddler صحبت کنیم.
تصویر زیر، نواحی اصلی ای که با آن ها سرو کار داریم را نمایش می دهد:
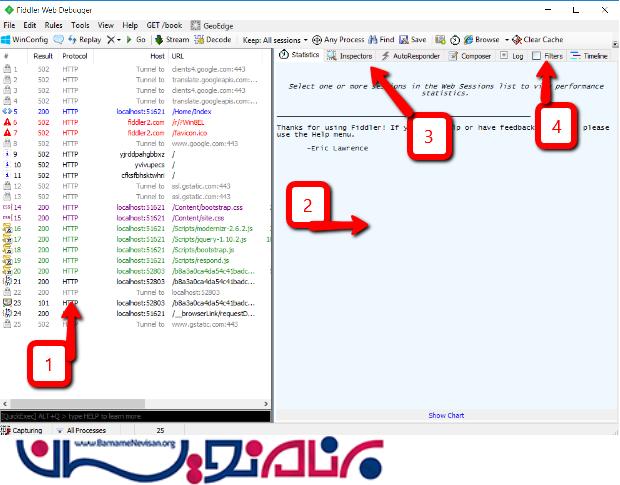
1-در سمت چپ، هر ترافیکی که وجود دارد توسط Fiddler نمایش داده می شود. این ترافیک شامل صفحه اصلی، و هر thread موجود است. شما می توانید از Fiddler استفاده کنید تا ببینید حجم ترافیک بر روی صفحه ، مربوط به کدام المان در صفحه است.
2-زمانی که بر روی یکی از آیتم هایی که در سمت چپ نشان داده شده اند، کلیک کنید، می توانید جزئیات مربوط به آن را در سمت راست ببینید.
3- بیشترین قسمتی که از آن استفاده می شود ، Inspectors است که با کمک آن می توان محتوای داده/ صفحه هایی که می خواهیم را ببینیم.
4-در ناحیه ی filters شما می توانید سایت هایی که می خواهید را فیلتر کنید تا دسترسی به url های خاصی بسته شود.
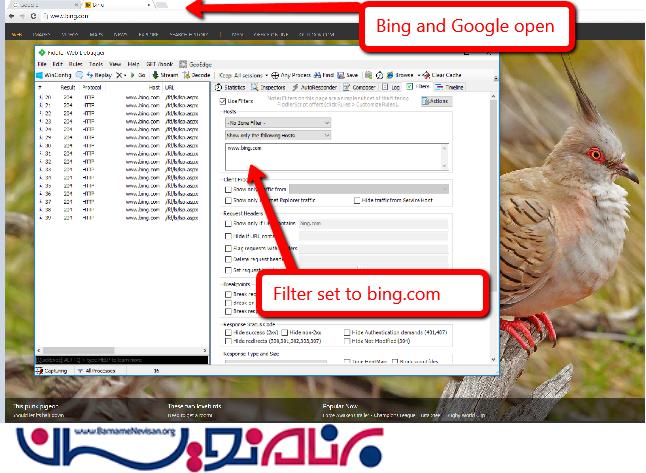
برای تست این مورد، می توانید در شکل زیر ببینید که من هم Bing و هم Google را باز کرده ام. اما چون فیلتر را بر روی Bing قرار داده ام، فقط موارد مربوط به آن نمایش داده می شوند:
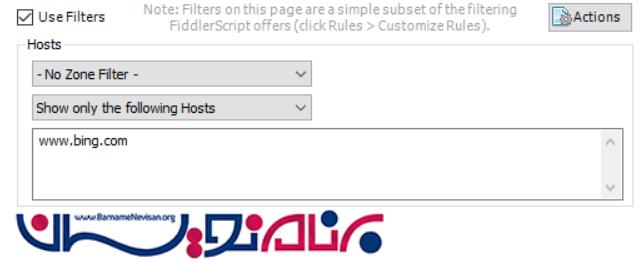
در زیر، مکانی که فیلتر بر روی آن گذاشته می شود، نشان داده شده است :
قبل از این که به سراغ مبحث بعدی برویم، بیایید inspectors را هم مورد بررسی قرار بدهیم. در این ناحیه، ما می توانیم جزئیات مربوط به ترافیک صفحه را ارزیابی کنیم.
بخش inspector به دو بخش تقسیم شده است. بخش بالا ، اطلاعاتی راجع به درخواست هایی که در حال ارسال هستند به ما می دهد. در اینجا ما در حال ارزیابی request header ها، جزئیات داده هایی که در حال ارسال هستند ، Cookie ها، داده ی json/xml و محتوای هر بخش هستیم. بخش پایینی اطلاعات مربوط به پاسخ هایی که از سمت سرور دریافت شده اند را نمایش می دهد که می تواند انواع مختلفی از داده ها را شامل شود.
نصب
برای این که بتوانیم این مقاله را در قالب Controller پیاده سازی کنیم، از یک پروژه MVC ساده استفاده می کنیم که پایه و اساسی برای کاوش وب سایت ما باشد. در زیر طریقه نصب و تنظیمات آن آورده شده است
یک کلاس به نام SampleDataمی سازیم که اطلاعات ساده ای که برای وب کاوی نیاز داریم را درون خودش نگهداری می کند. این کلاس، شامل لیستی از افراد و کشورها و رابطه ای بین این دو است.
public class PersonData
{
public int ID { get; set; }
public string PersonName { get; set; }
public int Nationality { get; set; }
public PersonData(int id, int nationality, string Name)
{
ID = id;
PersonName = Name;
Nationality = nationality;
}
}
public class Country
{
public int ID { get; set; }
public string CountryName { get; set; }
public Country(int id, string Name)
{
ID = id;
CountryName = Name;
}
}
سپس داده ها از طریق سازنده (Constructor ) به برنامه اضافه می شوند:
public class SampleData
{
public List<country> Countries;
public List<persondata> People;
public SampleData()
{
Countries = new List<country>();
People = new List<persondata>();
Countries.Add(new Country ( 1, "United Kingdom" ));
Countries.Add(new Country ( 2, "United States" ));
Countries.Add(new Country(3, "Republic of Ireland"));
Countries.Add(new Country(4, "India"));
..etc..
People.Add(new PersonData(1, 1,"AJSON"));
People.Add(new PersonData(2, 2, "Fred"));
People.Add(new PersonData(3, 2, "Mary"));
..etc..
}
}
</persondata>
ما Controller را به روش زیر کدنویسی می کنیم تا بتواند از داده ها استفاده کند:
public ActionResult FormData()
{
return Redirect("/home/index");
}
و یک page view داریم که آن را به کاربر نمایش می دهیم :
@model SampleServer.Models.SampleData
<table border="1" id="PersonTable">
<thead>
<tr>
<th>
<pre lang="html">
Persons name</pre>
</th>
<th>
<pre>
View detail</pre>
</th>
</tr>
</thead>
<tbody>
@foreach (var person in @Model.People)
{
<tr>
<td>
@person.PersonName
</td>
<td>
<pre>
<a href="/home/detail/@person.ID">view </a>
</td>
</tr>
}
</tbody>
</table>
همچنین ما یک فرم دیگر نیز ایجاد می کنیم تا بتوانیم از طریق آن ، ارسال داده ها را تست کنیم.
<form action="/home/FormData" id="dataForm" method="post"><label>Username</label> <input id="UserName" name="UserName" value="" /> <label>Gender</label> <select id="Gender" name="Gender"><option value="M">Male</option><option value="F">Female</option></select> <button type="submit">Submit</button></form>
در نهایت، به دو controller/view-page دیگر نیاز داریم.
Controller ها:
public ActionResult ViewDetail(int id)
{
SampleData SD = new SampleData();
SD.SetSelected(id);
return View(SD);
}
public ActionResult FormData()
{
var FD = Request.Form;
ViewBag.Name = FD.GetValues("UserName").First();
ViewBag.Gender = FD.GetValues("Gender").First();
return View("~/Views/Home/PostSuccess.cshtml");
}
View ها :
Success! .. data received successfully. @ViewBag.Name @ViewBag.Gender
@model SampleServer.Models.SampleData
<label>Selected person: @Model.SelectedName</label>
<label>Country:
<select>
@foreach (var Country in Model.Countries)
{
if (Country.ID == Model.SelectedCountryID)
{<option selected="selected" value="@Country.ID">@Country.CountryName</option>
}
else
{<option value="@Country.ID">@Country.CountryName</option>
}
}
</select></label>
زمانی که سرور مان را اجرا می کنیم، تعدادی داده داریم که می توانیم بر روی آن ها عملیات خزیدن را انجام بدهیم.
مبانی خزیدن در وب
در ابتدای مقاله اشاره کردیم که خزیدن در وب، یک فرآیند چند مرحله ای است. مثالی که ما در این مقاله در مورد آن صحبت می کنیم، مثال کوچکی است اما به صورت کلی، روند کار به این صورت است که به دنبال محتویات صفحه می گردیم . در اینجا می توانیم از Fiddler استفاده کنیم.
زمانی که مرورگر شما باز است و Fiddler در حال ارزیابی سایتی است که می خواهید در آن به کاوش و خزیدن بپردازید، ترافیک و همچنین روند کلی سایت توسط Fiddler ارزیابی می شود. سپس می توانید داده هایی که توسط Fiddler تهیه شده اند را مورد استفاده قرار بدهید.
خزیدن در وب سایت به این صورت است شما به یک صفحه می روید و داده های آن را واکشی می کنید. معمولا داده ها درون یک صفحه وب پراکنده هستند و شما نیاز دارید تا روند تعامل کاربر با وب سایت را از طریق مهندسی معکوس، آنالیز کنید تا به این ترتیب بتوانید هر چه بیشتر به مواردی که در خزیدن در آن سایت، می خواهید به آن ها دست پیدا کنید، نزدیک شوید. همچنین شما ممکن است در طی این فرآیند، متوجه شوید که اطلاعات به صورت مستقیم و با استفاده از فراخوانی های سمت سرور بر روی صفحه چیده نمی شوند، بلکه به وسیله یک فراخوانی Ajax و یا متدهای JavaScript این کار انجام می شود. در تمامی این حالات، Fiddler می تواند به شما کمک های بسیاری کند ، تا هم بتوانید وقایعی که در مرورگر در حال رخ دادن است را مشاهده و بازرسی کنید و هم از ترافیک شبکه خودتان آگاه شوید. تجربیات شخصی مهندسین باتجربه نشان داده است که می تواند روند کاری و بررسی داده ها را با کمک یک فلوچارت به راحتی ثبت و بررسی کرد.
زمانی که در حال آنالیز و تلاش برای انجام عمل خزیدن در یک سایت هستید، به مواردی که به صورت پنهان در سایت وجود دارند، توجه کنید. به عنوان مثال، نگهداری session-state و موقعیت کاربر در وب سایت، در سمت سرور، چندان جالب نیست. در این مورد، شما نمی توانید به سادگی به کاوش داده ها در وب سایت بپردازید و مجبورید طبق اجبار سایت، عمل کنید، زیرا در چنین مواردی یک نظم و روش خاص در وب سایت وجود دارد که کاربر به وسیله آن به صفحات، هدایت می شود. اگر در یک سایت که دارای قوانین خاصی است، به دنبال رفتن و کاوش اطلاعات از یک صفحه خاص هستید، برای شناسایی صفحه می توانید از مواردی نظیر css ها استفاده کنید.
موثر ترین نکته در خزیدن در وب سایت ها این است که بخش های مختلف سایت را به موارد کوچک و جزئی تقسیم کنید و سپس برای کاوش آن ها از الگوهای Fiddler استفاده کنید.
Web scraping در بخش client
برای این مقاله ، ما یک پروژه کنسول ساده ایجاد کرده ایم که به عنوان بخش scrape client ما عمل می کند. اولین کاری که باید انجام بدهیم این است که کتابخانه ScrapySharp را از طریق nugget به پروژه اضافه کنیم. با استفاده از دستور زیر می توانیم این کار را انجام بدهیم :
PM> Install-Package ScrapySharp using ScrapySharp.Network; using HtmlAgilityPack; using ScrapySharp.Extensions;
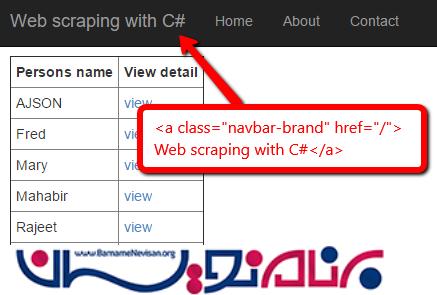
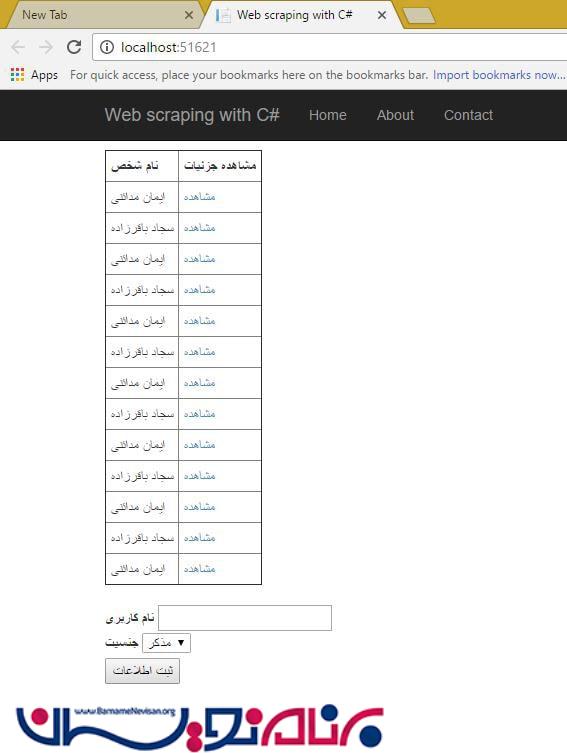
برای این که عملکرد برنامه را ببینید ، برنامه ی MVC sample server را اجرا کنید . همان طور که در شکل زیر می بینید، می توانیم به وسیله ی عنوان صفحه که یکتا است و مشابهی ندارد، به خزیدن و کاوش داده ها در این صفحه خاص بپردازیم.
در کنسول، یک شی ScrapingBrowser ایجاد می کنیم (که مرورگر مجازی ما است ) و موارد پیش فرضی که می خواهیم را برای آن تنظیم می کنیم. به عنوان مثال، تنظیمات زیر می توانند اعمال شوند:
ScrapingBrowser Browser = new ScrapingBrowser(); Browser.AllowAutoRedirect = true; // Browser has settings you can access in setup Browser.AllowMetaRedirect = true;
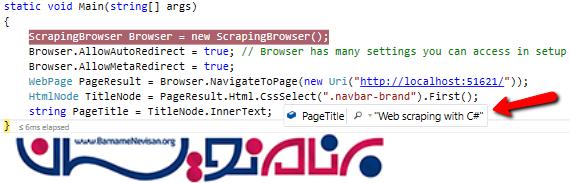
مرحله بعدی این است که به مرورگر بگوییم قصد بارگذاری چه صفحه ای را داریم و سپس از ویژگی بسیار موثر CssSelect استفاده کنیم و المانی که می خواهیم را پیدا کرده و کاوش کنیم. نتایج تحقیقات نشان داده است که معمولا عنوان های موجود در صفحه، دارای یک کلاس منحصر بفرد هستند. بنابراین می توانیم در عملیات مورد نظرمان از آن ها استفاده کنیم. دسترسی ما به موارد درون صفحه معمولا با استفاده از HTMLNode ها انجام می شود.
WebPage PageResult = Browser.NavigateToPage(new Uri("http://localhost:51621/"));
HtmlNode TitleNode = PageResult.Html.CssSelect(".navbar-brand").First();
string PageTitle = TitleNode.InnerText;
و مکان قرار گیری آن در برنامه به صورت زیر خواهد بود:
مورد بعدی که باید انجام بدهیم این است که مجموعه ای از آیتم ها را مورد پردازش و کاوش قرار بدهیم، به عنوان مثال، نام هایی که درون جدول قرار دارند. برای انجام این کار، لیستی از جنس string ایجاد می کنیم که داده ها را بگیرد، و سپس با یک کوئری ، نتایجی که می خواهیم را در صفحه نمایش می دهیم. در اینجا ما می خواهیم نام افراد را نمایش بدهیم، بنابراین از پارامتر [1] index استفاده می کنیم.
List<string> Names = new List<string>();
var Table = PageResult.Html.CssSelect("#PersonTable").First();
foreach (var row in Table.SelectNodes("tbody/tr"))
{
foreach (var cell in row.SelectNodes("td[1]"))
{
Names.Add(cell.InnerText);
}
}
</string>
و خروجی ای که ما انتظار داریم:
AJSON
Fred
Mary
Mahabir
Rajeet
Philippe...
مورد آخری که برای این مقاله در نظر داریم، دریافت و سپس ارسال یک فرم است. برای این کار، فرم را مسیردهی می کنیم و سپس کارهایی که می خواهیم را بر روی آن انجام می دهیم . برای این که بتوانیم از فرم ها استفاده کنیم، نیاز داریم فضای نام زیر را اضافه کنیم:
using ScrapySharp.Html.Forms;
در اکثر موارد شما می توانید از روی html source صفحه ، نام فیلد های مورد نظرتان را پیدا کنید. ولی در برخی موارد به دلایل امنیتی و یا محدودیت های اعمال شده توسط فایل های javascript ، نمی توانید این کار را انجام دهید. در چنین مواردی می توانید برای پیدا کردن نام فیلدها و مقادیر، از Fiddler استفاده کنید.
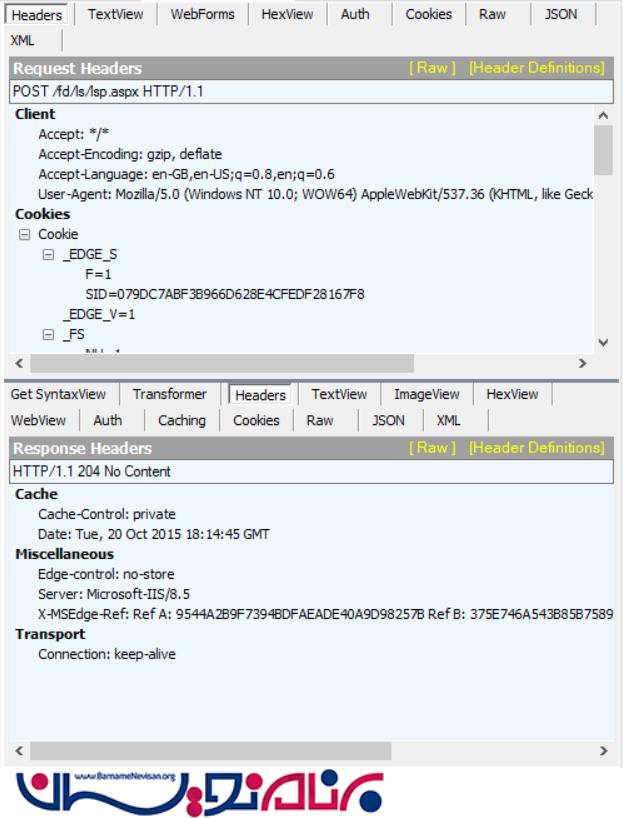
در تصویر زیر می توانید ببینید که فرم در درخواست فرستاده می شود و سپس پاسخ از جانب سرور بازگردانده می شود:
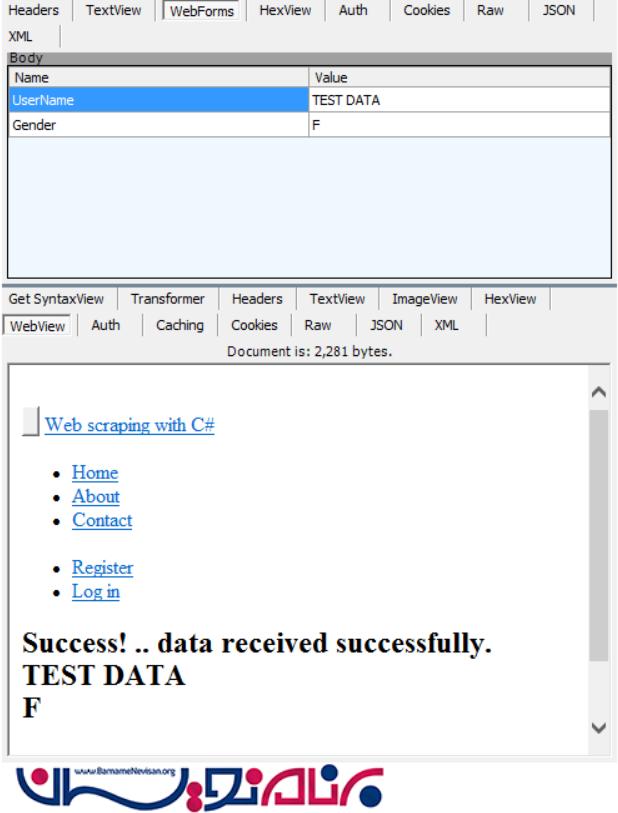
کدهایی که برای محل قرار گیری فرم و همچنین ارسال داده های داخل آن نوشته می شوند، به شرح زیر هستند:
// find a form and send back data
PageWebForm form = PageResult.FindFormById("dataForm");
// assign values to the form fields
form["UserName"] = "AJSON";
form["Gender"] = "M";
form.Method = HttpVerb.Post;
WebPage resultsPage = form.Submit();
نکته مهمی که لازم است بگوییم این است که در هنگام ارسال فرم از صحت اطلاعات وارد شده مطمئن شوید و همچنین مطمئن شوید که مقادیر مربوط به پاسخ را دریافت می کنید. (به این معنا که جواب از سمت سرور، حتما به برنامه شما می رسد.)
دانلود فایل های باینری از وب سایت ها
دریافت و ذخیره فایل های باینری، مانند PDF ها، بسیار کار ساده ای است. ما URL را وارد می کنیم و سپس فایلی که به سمت ما فرستاده می شود را در قالب 'raw' response body دریافت می کنیم. در زیر یک مثال از این کارآورده شده است:
WebPage PDFResponse = Browser.NavigateToPage(new Uri("MyWebsite.com/SomePDFFileName.pdf"));
File.WriteAllBytes(SaveFolder + FileName, PDFResponse.RawResponse.Body);

- C#.net
- 5k بازدید
- 6 تشکر