نحوه ساخت پست های شبکه های اجتماعی از محتوای طولانی با استفاده از پایتون
سه شنبه 17 فروردین 1400این مقاله در مورد تولید پستهای شبکه های اجتماعی از محتوای نوشتاری طولانی با استفاده از پایتون است.

بیشتر شرکتها به عنوان بخشی از ابتکار بازاریابی خود، بلاگهای فنی و مقالاتی را ایجاد میکنند. و آنها این مطالب را به صورت خلاصه در رسانههای اجتماعی قرار میدهند، که به آنها کمک میکند تا مشتریان را به وبسایتهایشان هدایت کنند. این راهحل به شما کمک میکند تا از طریق مقالات یا پستهای بلاگ، چنین پستهایی را برای شبکه های اجتماعی بسازید.
در این مقاله یاد میگیرید که چگونه یک سولوشن را با استفاده از Python و Flask و هاستینگ آن در Azure App Service پیاده سازی کنید. همچنین یاد میگیرید که به جای استفاده از nltk package از Azure Cognitive Services استفاده کنید.
چگونه کار میکند؟
الگوریتم بسیار ساده است. ابتدا URL را تبدیل می کنید و بعد با استفاده از NLP کلمات کلیدی را از محتوا استخراج میکنید. در ادامه جملات موجود در محتوا را با بیشتر کلمات کلیدی پیدا کرده و آن را نمایش میدهید.
در این مثال از پکیجهای زیر استفاده شده است.
Flask: برای رابط کاربری و تعاملات کاربر
Newspaper: برای دریافت محتوا از URLها یا وبسایت
Nltk: برای استخراج کلمات کلیدی از متن و تقسیم محتوا به چندین جمله
بنابراین شما باید پکیجهای فوق را نصب کنید. در اینجا فایل requirements.txt وجود دارد.
Flask==1.1.2
newspaper3k==0.2.8
nltk==3.5میتوانید pip install -r requirements.txt را در محیط مجازی خود اجرا کنید. پس از نصب همه ملزومات، میتوانید فایل app.py را بسازید. شما میتوانید فایل app.py را در بخش پیادهسازی پیدا کنید. میتوانید از VS Code برای اهداف توسعه، با اکستنشنهای Docker و Azure استفاده کنید.
پیاده سازی
میتوانید از فریم ورک Flask برای نشان دادن رابط کاربری و تعامل با ورودیهای کاربر استفاده کنید. پکیج newspaper برای تبدیل URL به فرمت قابل خواندن و استخراج کلمات کلیدی از محتوا با استفاده از پکیج Nltk است.
from flask import Flask, render_template, request
import newspaper
import nltk
from nltk.tokenize import sent_tokenize
app = Flask(__name__)
@app.route('/', methods=['GET'])
def index():
return render_template('index.html')
@app.route('/', methods=['POST'])
def index_post():
url = request.form['UrlInput']
if(len(url.strip()) >= 1):
article = newspaper.Article(url)
article.download()
article.parse()
article.nlp()
sentences = sent_tokenize(article.text)
keywords = article.keywords
results = []
frequency = 3
for sentence in sentences:
numberOfWords = sum(
1 for word in keywords if word in sentence)
if (numberOfWords > frequency):
results.append(sentence.replace("\n", "").strip())
return render_template('result.html', url=url, results=results, keywords=keywords)
else:
return render_template('result.html', url=url, error='Please provide a valid URL to continue.')
if __name__ == '__main__':
app.run(host='0.0.0.0', port=5000)این پیادهسازی یک مسیر با HTTP methodهای مختلف به دست میآورد. وقتی کاربر URL را بررسی میکند، متد HTTP GET فراخوانی میشود و یک فایل index.html را برمیگرداند. و هنگامی که کاربر فیلد UrlInput را پر میکند و فرم را ارسال میکند، مسیر HTTP POST فراخوانی میشود. در backend، مقدار فیلد فرم UrlInput را دریافت خواهید کرد. با استفاده از پکیج URL ،Newspaper دانلود میشود، با کمک nltk که به استخراج کلمات کلیدی کمک میکند nlp بر روی محتوا تبدیل و اجرا میشود. بعد با استفاده از sent_tokenize متن به چندین جمله تقسیم میشود. و در آخر، بر اساس تعداد کلمات کلیدی در یک جمله، جمله را به یک آرایه اضافه کنید و فایل result.html را با آرایه رندر کنید. و برنامه پورت 5000 را نشان میدهد. شما میتوانید برنامه را با استفاده از VS Code اجرا یا دیباگ کنید.
در بخش بعدی، سولوشن را با Azure پابلیش میکنید.
پابلیش کردن با Azure
برای پابلیش سولوشن با Azure، بیاید سولوشن را به docker image تبدیل کرده و آن را پابلیش کنیم. برای این کار میتوانید از اکستنشن VSCode Docker استفاده کرده و Dockerfile را اضافه کنید. بعد از افزودن Dockerfile، فایل requirements.txt را با پکیجهای flask و gunicorn دریافت خواهید کرد. باید پکیجهایی که نصب کردهاید را به این قسمت اضافه کنید. مانند زیر فایل requirements.txt را تغییر دهید.
Flask==1.1.2
gunicorn==20.0.4
newspaper3k==0.2.8
nltk==3.5و در اینجا Dockerfile تولید شده توسط VS Code است.
FROM python:3.8-slim-buster
EXPOSE 5000
ENV PYTHONDONTWRITEBYTECODE=1
ENV PYTHONUNBUFFERED=1
COPY requirements.txt .
RUN python -m pip install -r requirements.txt
WORKDIR /app
COPY . /app
RUN useradd appuser && chown -R appuser /app
USER appuser
CMD ["gunicorn", "--bind", "0.0.0.0:5000", "app:app"]بعد از انجام این کار، دستور docker build image را اجرا کنید: docker image build --tag anuraj/postgenerator .، شما باید به جای anuraj از docker hub یا container registry id استفاده کنید. و بعد از اینکه build شد، کانتینر را با دستور docker run -d -p 5000:5000 anuraj/postgenerator اجرا کنید و مرورگر را باز کرده و بررسی کنید ببینید آیا برنامه ما در حال اجراست. شما میتوانید http://127.0.0.1:5000/ را بررسی کنید. این رابط کاربری را نشان خواهد داد. بعد از ارسال URL، خطای داخلی سرور ایجاد میشود. شما میتوانید لاگهای داکر را بررسی کنید و مواردی را به این صورت نشان دهید.
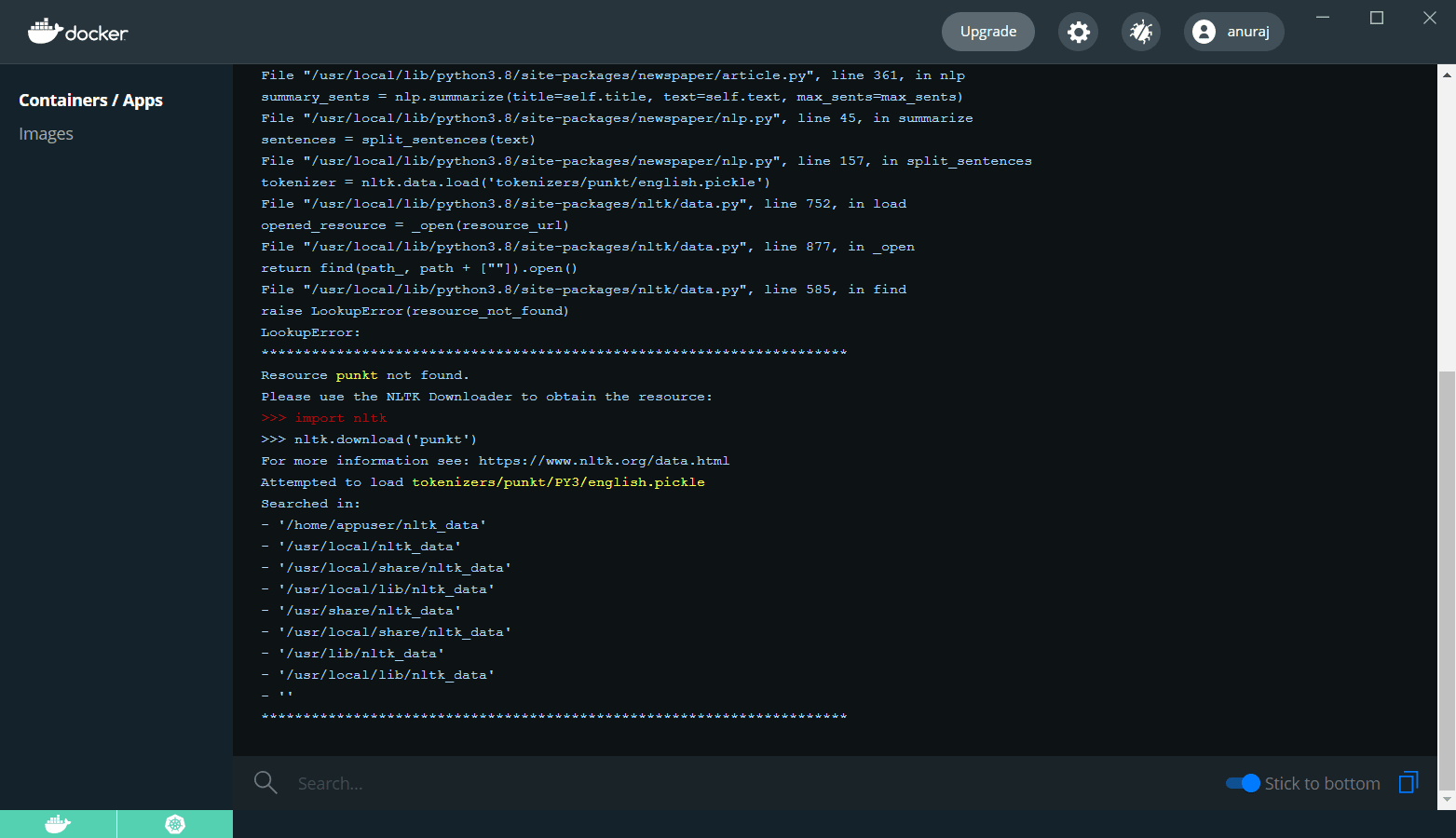
برای رفع این مشکل، باید منبع punkt را دانلود کنید. میتوانید در Dockerfile این کار را به این صورت انجام دهید.
FROM python:3.8-slim-buster
EXPOSE 5000
ENV PYTHONDONTWRITEBYTECODE=1
ENV PYTHONUNBUFFERED=1
COPY requirements.txt .
RUN python -m pip install -r requirements.txt
WORKDIR /app
COPY . /app
RUN [ "python", "-c", "import nltk; nltk.download('punkt', download_dir='/app/nltk')" ]
ENV NLTK_DATA /app/nltk/
RUN useradd appuser && chown -R appuser /app
USER appuser
CMD ["gunicorn", "--bind", "0.0.0.0:5000", "app:app"]در Dockerfile شما در حال دانلود منبع punkt در پوشه /app/nltk هستید و متغیر محیطی NLTK_DATA را در پوشه دانلود شده کانفیگ میکنید. اکنون ایمیج را بسازید و آن را اجرا کنید. باید به درستی کار کند. اکنون شما یک داکر ایمیج ساخته اید. سپس باید ایمیج را برای هر رجیستر داکری پابلیش کنید. برای این مثال، از Docker Hub استفاده شده است. و ایمیج بر اساس اکانت Docker Hub برچسبگذاری شده است. اگر از قراردادها پیروی نکنید، باید ایمیج را با id خود برچسبگذاری کنید. اگر از VS Code استفاده میکنید، میتوانید با کمک Docker extension آن را از آنجا deploy کنید یا میتوانید از دستور docker push استفاده کنید، به این صورت: docker push anuraj/postgenerator، ممکن است بر اساس پهنای باند اینترنت تان مدتی طول بکشد.
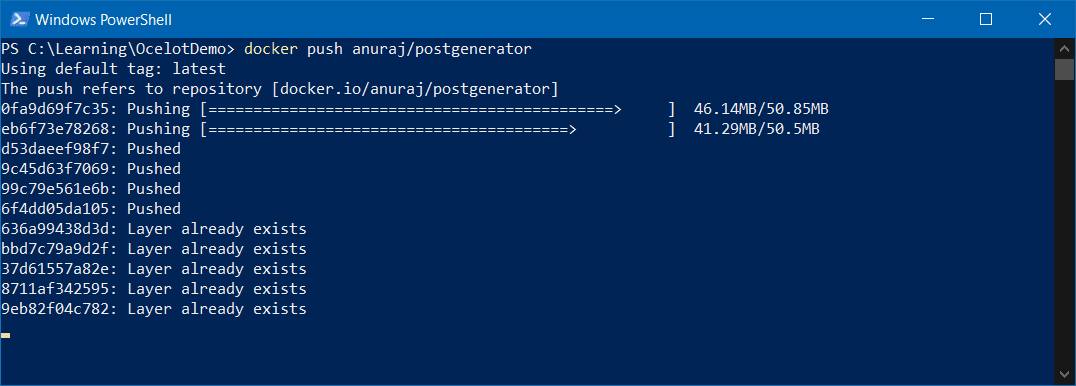
پس از اتمام، میتوانید Docker Hub را بررسی کرده و ببینید که در دسترس است. برای deploy کردن ایمیج در App Service، می توانید از اکستنشن VS Code Docker استفاده کنید، میتوانید بر روی image tag کلیک راست کرده و گزینه Deploy Image to Azure App Service را انتخاب کنید.
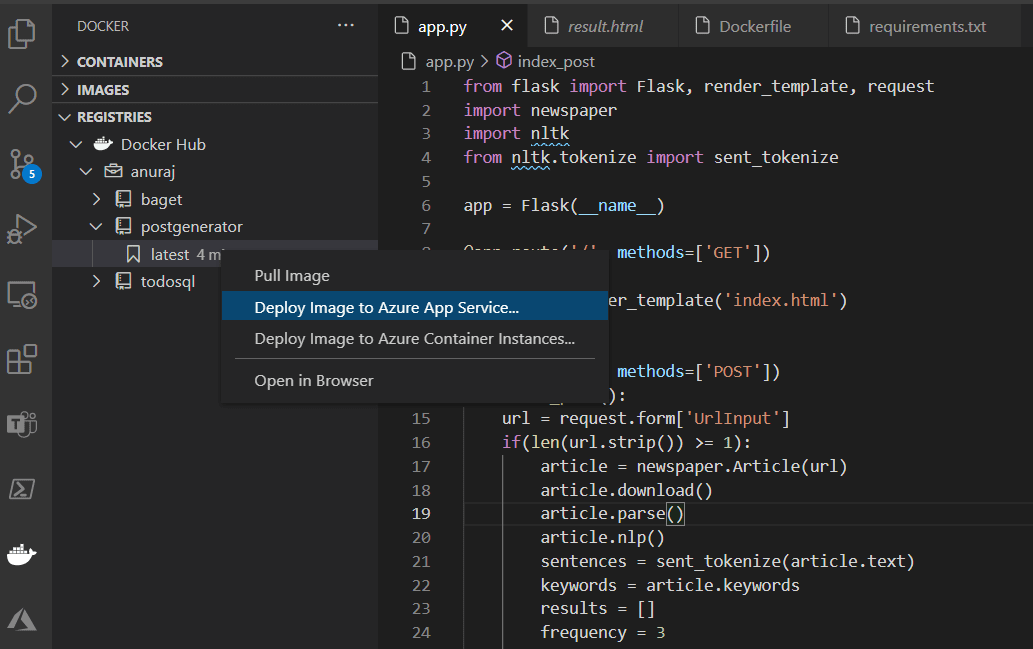
این برخی از مقادیر کانفیگ را به فعالیت وا می دارد؛ شبیه همان چیزی که هنگام ساخت Azure App Service کانفیگ کردید. پس از اتمام کار، VS Code، app service را ارائه میدهد و کانتینر ایمیج را در deploy ،Azure app service میکند.
بهبودها
شما میتوانید پیاده سازی را با استفاده از Azure Cognitive Services - Text Analytics گسترش دهید. بنابراین به جای استفاده از پکیج nltk برای استخراج کلمات کلیدی میتوانید از سرویس Azure Text Analytics و استخراج کلمات کلیدی استفاده کنید. در اینجا کد دریافت کلمات کلیدی با استفاده از Text Analytics از docs.microsoft.com وجود دارد.
from azure.core.credentials import AzureKeyCredential
from azure.ai.textanalytics import TextAnalyticsClient
credential = AzureKeyCredential("<api_key>")
endpoint="https://<region>.api.cognitive.microsoft.com/"
text_analytics_client = TextAnalyticsClient(endpoint, credential)
documents = [
"Redmond is a city in King County, Washington, United States, located 15 miles east of Seattle.",
"I need to take my cat to the veterinarian.",
"I will travel to South America in the summer."
]
response = text_analytics_client.extract_key_phrases(documents, language="en")
result = [doc for doc in response if not doc.is_error]
for doc in result:
print(doc.key_phrases)لطفا توجه کنید که Text Analytics محدودیتهای داده های درخواست را دریافت میکند؛ حداکثر تعداد کاراکترها برای یک سند 5120 و حداکثر تعداد اسناد 10 است. بنابراین اگر میخواهید کلمات کلیدی را از اسناد طولانی استخراج کنید، ممکن است لازم باشد سند را تقسیم کنید و نتایج را متصل کنید.
اکنون شما حداقل برنامه python AI را پیاده سازی کرده و بر روی Azure آن راdeploy کردهاید.
اگر به یادگیری زبان پایتون علاقه دارید، میتوانید از آموزش رایگان پایتون استفاده کنید.

- Python
- 2k بازدید
- 1 تشکر