معرفی Microsoft Sync Framework
دوشنبه 19 مهر 1395Microsoft Sync Framework ، یک پلتفرم گسترده همگام سازی است که برای دستگاه ها امکان همکاری آفلاین را فراهم می سازد .

Developer ها میتواند یک محیط همگام بسازند، که توانایی همگام کردن هر برنامه از هر داده ای از هر منبعی از هر پروتکلی و از هر شبکه را داشته باشد. ویژگی های تکنولوژی Sync FrameWork و ابزار هایی که انتقال اطلاعات ، sharing T roaming را بصورت آفلاین فعال می کنند.
یکی از جنبه های کلیدی Sync FrameWork توانایی ساختن Providers های خصوصی است . Providers هر منبع اطلاعاتی را به شرکت کردن در پردازش Sync FrameWork قادر میسازند ، و اجازه همگام سازی peer-to-peer را میدهند .

Sync FrameWork ها شامل تعدادی از Providers ها میشوند که تعداد زیادی از منابع اطلاعاتی را support میکنند . برای به حداقل رساندن توسعه ، توصیه می شود که توسعه دهندگان هر جایی که ممکن بود از این Providerها استفاده کنند ، اگرچه آنها اجباری نیستند . در قسمت زیر محتوای providerها را میبینید :
• Database synchronization providers : همگام سازی برای فعال سازی ADO.Net منابع داده
• File synchronization provider : همگام سازی برای فایل ها و فولدر ها
• Web synchronization components : همگام سازی برای FeedSync تغذیه مانند RSS و ATOM
بالاخره توسعه دهندگان میتوانند از ارائه دهندگان خارجی (out-of-the-box) استفاده کنند یا می توانند ارائه دهندگان سفارشی برای تغییر اطلاعات بین دستگاه و برنامه ، ایجاد کنند .
هدف از این مقاله ، معرفی "microsoft sync framework چگونه قادر به همگام سازی است " ، است . در این مقاله ، برخی از مفاهیم کلیدی است که پایه و اساس نحوه ایجاد فرم رئوس مطلب یک ارائه دهنده است .
• Participants (شرکت کنندگان) :
قبل از بحث در مورد عناصر یک ارائه دهنده ، ما نیاز داریم که انواع نوع داده ی شرکت کنندگان که ارائه دهنده از آن پشتیبانی میکند ، را بشناسیم . یک شرکت کننده مکانی است که اطلاعات از منبع داده بازیابی شده است . یک شرکت کننده میتواند هر چیزی از یک سرویس دهنده وب ، به یک لپ تاب ، به یک درایو فلش USB ، باشد .
• انواع Participants :
بر اساس قابلیت های دستگاه ، راه های ادغام هماهنگ سازی ارائه میدهد متفاوت خواهد بود . حداقال ، ما فرض میکنیم که در زمان درخواست دستگاه قادر به برنامه نویسی بازگشت اطلاعات خواهد بود . در نهایت آن چیزی که باید تعیین شود چیزی است که دستگاه قادر به آن است :
1. داده ها را قادر به ذخیره شدن و نگهداری در دستگاه های موجود میکند .
2. به برنامه ها این اجازه را می دهند که مستقیما از طرف دستگاه اجرا شوند .
تشخیص نوع شرکت کنندگان مهم است که ، بخشی از اکوسیستم هماهنگسازی خواهد بود ، به این دلیل مهم است که اگر توانایی ذخیره سازی اطلاعات مورد نیاز توسط ارائه دهنده را دارد ، به ما میمیگوید ، همچنین اگر ما توانایی اجرای Provider را به صورت مستقیم از دستگاه داریم ، به ما میگوید . سرانجام ، مدلی از شرکت کنندگان به معنای generic بودن است . همینطور ، یک شکرت کننده کامل میتواند طوری پیکربندی شود که یک شرکت کننده ساده و جزئی باشد .
شرکت کنندگان کامل :
شرکت کنندگان کامل ، دستگاههایی هستند که به توسعه دهندگان اجازه ایجاد برنامه ها و انبار ها را بصورت مستقیم بر روی دستگاه ها میدهند. لپ تاپ یا یه گوشی هوشمند ، نمونه ای از شرکت کننده کامل میباشد ، به این دلیل که برنامه های جدید بصورت مستقیم میتوانند دردستگاه اجرا شوند و اگر نیاز بود، انباره ای جهت ذخیره سازی اطلاعات مورد نیاز نیز ایجاد میکند .

شرکت کنندگان جزئی :
شرکت کنندگان جزئی دستگاههایی هستند که توانایی ذخیره سازی اطلاعات بر روی یک انبار اطلاعات موجود در سیستم یا یک انبار اطلاعات موجود ذخیره سازی کنند . این دستگاهها، اگرچه ، توانایی اجرای مستقیم از دستگاه را ندارند . اگر مثالی را بخواهیم برای این دستگاهها ارائه دهیم ، میتوانیم به SD Cardها اشاره کنیم . این دستگاه ها شبیه hard driveها عمل می کنند که اطلاعات میتوانند ، ایجاد ، بروزرسانی و حذف شوند . اگرچه ، آنها یک رابط را میدهند که اجازه اجرای برنامه بصورت مستقیم بر روی آنها را میدهد .
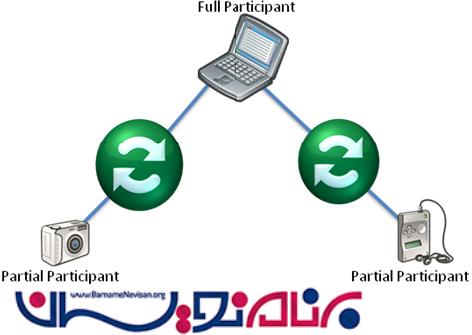
شرکت کنندگان ساده :
شرکتکنندگان ساده دستگاههایی هستند که فقط قادر به فراهم آوردن اطلاعات در زمان درخواست هستند . این دستگاهها توانایی ذخیرهسازی و نگهداری از داده های جدید را ندارند و نمیتوانند برنامه جدیدی راایجاد کنند .
RSS Feesها و فراهم آورنده Web Service بوسیبه یک سازماندهی خارجی همانند Amazon یا EBay ، نمونه ای از شرکتکنندگان ساده هستند . این سازمان ها این توانایی را برای شما فراهم میکنند که web serviceهایی را اجرا کنید و نتیجه اش را دریافت نمایید، اگرچه، آنها به شما توانایی ایجاد یک انبار ذخیره سازی اطلاعات جدید را نمیدهند همچنین آنها اجازه ایجاد برنامه جدیدی که با Web serverهای آنها قابل اجرا باشد را نیز نمیدهند .

جمع آوری :
سرانجام هدف Microsoft Sync Framework این است که هر منبع داده ای بدون در نظر گرفتن نوع شرکتکننده آن ، یکپارچه باشد . برای همین ، شرکت کنندگان جزئی (partial participants) میتوانند بوسیله شرکت کنندگان کامل اطلاعات را همگام سازی کنند ، و شرکت کنندگان کامل به کمک شرکت کنندگان ساده میتوانند همگام سازی اطلاعات را انجام دهند . حداقل در اینجا ، به یک شرکت کننده کامل که توانایی ذخیرسازی اطلاعات و اجرای پردازش های همگام سازی را دارد ، نیاز است .
Microsoft Synchronization Framework :
اجزای اصلی :
قبل از پیاده سازی همگام سازی با استفاده از Sync Framework ، این امر نیاز میشود که ما کلید های اصلی یک provider را بشناسیم . شکل زیر ، چگونگی ساخته شدن provider توسط Sync Framework مرتبط با یک منبع داده را نشان میدهد .
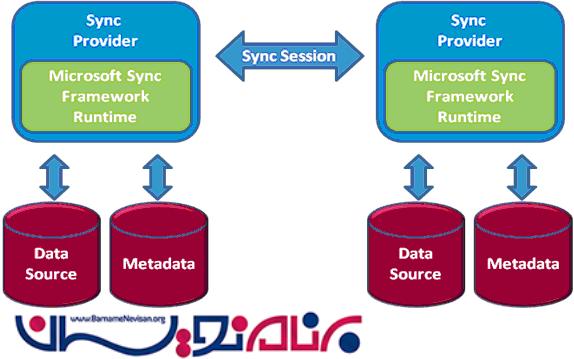
منبع داده :
منبع داده مکانی است که تمام اطلاعاتی که باید همگام سازی شوند ، در آنجا قرار دارند . یک منبع داده میتواند یک پایگاه داده رابطه ای ، یک فایل و یا یک web service باشد . تا زمانی که شما با برنامه نویسی به داده ها دسترسی دارید ، میتوانید آنها را همگام سازی کنید .
Metadata :
یکی از مولفه های پایه و اساسی یک provider ، توانایی ذخیره سازی اطلاعات در مورد منبع داده و اشیاء آن منبع است . Metadataها میتوانند در یک فایل ، در یک منبع داده یا یک انبار داده همگام سازی شده ، ذخیره شوند . برای راحتی کار ، Sync Framework یک پیاده سازی از یک انبار metadata که بر روی یک پایگاه داده سبک که بر روی پردازش شما اجرا میشود ، ساخته شده است را پیشنهاد میدهد . یک metadata میتواند به پنج مولفه اصلی برای انبار داده ، شکسته شود :
• Versions
• Knowledge
• Tick count
• Replica ID
• Tombstones
برای هر آیتمی که همگام سازی میشود ، یکسری اطلاعات ذخیره میشود که توضیح میدهد که اطلاعات در کجا و در چه زمانی تغییر پیدا کردند . این metadataها در دو نسخه نوشته میشوند : یک نسخه ایجاد و یک نسخه بروزرسانی . یک نسخه از دو مولفه تشکیل شده است : یک tick count توسط انبار داده و replica ID برای انبار داده اختصاص داده شده است . چنان که آیتم بروزرسانی شد ، tick count جاری برای آیتم درخواست داده میشود و tick count توسط انبار داده افزایش مییابد . replica ID یک مقدار منحصر به فرد است که انبار داده ی خاصی را مشخص میکند . زمانی که item ساخته شد، نسخه ایجاد با نسخه بروزرسانی یکسان است . تغییرات بعدی برای item ، نسخه بروزرسانی را دوباره با نسخه ایجاد متفاوت میکنند .
دو راه اصلی برای پیاده سازی نسخه ها عبارتاند از :
1. ردیابی خطی : در این متد تغییر اطلاعات ردیابی برای یک item ، مصادف با بروزرسانی اطلاعات ایجاد آن است .
در مورد یک پایگاه داده ، برای مثال ، برای بروزرسانی سریع و بلافاصله ی جدول ردیابی بعد از ایجاد تغییر در آن ، ممکن است از trigger استفاده کنیم .
2. ردیابی ناهمگام : در این متد ، یک پردازش خارجی وجود دارد که اجرا و دنبال تغییرات میگردد . هرگونه بروزرسانی که پیدا شود به نسخه دانش ، اضافه میشود . این فرآیند ممکن است یک پردازش برنامه ریزی شده باشد یا اینکه قبل از همگام سازی اجرا شود . از این فرآیند معمولا زمانی که هیچ مکانیزم داخلی برای بروزرسانی نسخه دانش در زمانی که در itemها تغییراتی ایجاد میشود وجود ندارد ، استفاده میشود . یکی از راه های برای چک کردن تغییرات این است که وضعیت itemها را ذخیره کنیم و با وضعیت الانِ آن مقایسه کنیم .
همه تغییرات-ردیابی حداقل باید در سطح item رخ بدهد . به عبارت دیگر ، هر item باید یک نسخه دانش داشته باشد . در مورد یک نسخه از پایگاه داده ، یک item ممکنه مساوی با یک سطر از یک جدول است . متناوبا ، ممکن است مساوی با یک ستون از یک سطر جدول باشد . در مورد فایل همگام سازی ، یک item شبیه یک file خواهد بود .
یکی دیگر از مسائل کلیدی که نیاز است ما به آن بپردازیم ، notion of knowledge است . Knowledge یک نمونه فشرده از تغییرات است که Replica از آن آگاه است . به عنوان نسخه دانش بروزرسانی شده است ، بطوری که knowledge برای ذخیره داده کار میکند . providerها از replica knowledge برای کارهای زیر استفاده میکنند :
1. شمارش تغییرات
2. تشخیص تضادها
هر replica همچنین باید برای هر item ای که حذف شده است tomstoneای را نگهدارد . این امر بسیار مهمی است ، به این دلیل که ، زمانی که همگامسازی در حال اجراست ، اگر itemای وجود نداشته باشد ، هیچ راهی برای provider وجود ندارد که بگوید این item حذف شده است و نمیتواند تغییرات را به providerهای دیگر انتقال دهد . یک tombstone بایدشامل اطلاعات زیر باشد :
• Global ID.
• Deletion version (نسخه حذف)
• Creation version (نسخه ایجاد)
به دلیل اینکه تعداد tombstoneها به مرور زمان رشد خواهد کرد ، در اینجا باید روشی سنجیده برای حذف اینها بعد از یک مدت زمانِ مشخص ، برای حفظ فضای حافظه وجود داشته باشد . پشتیبانی برای مدیریت اطلاعات tombstoneها توسط Sync Framework ، انجام میشود .
جریان Synchronization :
replica در جایی که synchronization شروع میشود source نامیده میشود و جایی که replica به آن وصل میشود را destination میگویند . در زیر نمودار synchronization Flow را مشاهده میکنید . برای synchronization دوطرفه ، این پروسه دو بار اجرا میشود که در دورِ دوم اجرا جای source و destination عوض میشود .
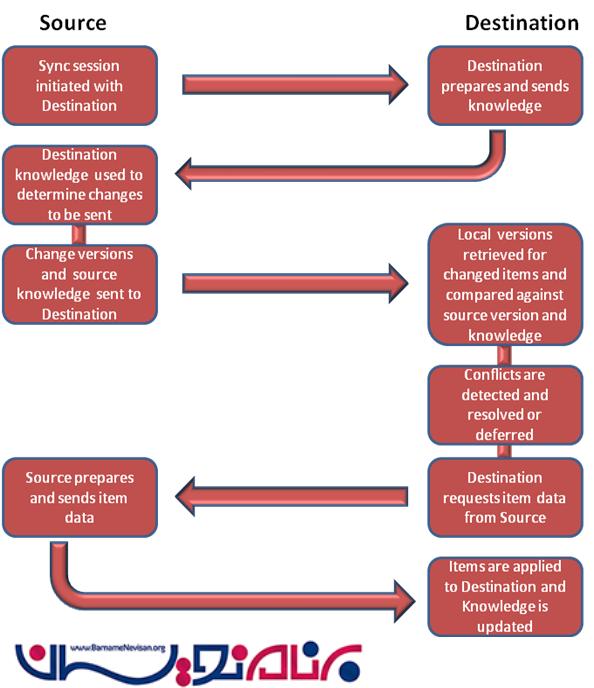
دوره همگام سازی با Destination آغاز میشود :
در طول این فاز ، source provider ارتباط با destination provider را آغاز میکند . لینک بین دو provider را دوره همگام سازی (synchronization session) میگویند .
آماده سازی destination و ارسال knowledge :
همانطور که قبلا ذکر کردیم ، هر replica در knowledge منحصر به فرد خودش ذخیره میشود . Knowledge ای که در destination ذخیره شده است به source ارسال میشود .
Destination Knowledge به منظور تخمین تغییرات برای ارسال ، استفاده میشوند :
در سمت Knowledge ، Sourceای که دریافت میشود با نسخه محلی item مقایسه میشود تا itemی که desination آن را نمیشناسد را ، تخمین بزند .
تغییر نسخه ها و ارسال به destination توسط Source Knowledge :
هنگامی که ، Source لیستی از تغییرات را آماده کرد ، آن را به destination ارسال میکند .
نسخه محلی برای itemهای تغییر یافته فراخوانی میشود , و با Source Version و Knowledge مقایسه میشود :
destination از نسخه ها برای تهیه لیستی از itemهایی که source به آنها نیاز دارد تا ارسال کنیم ، تهیه میکند .
Conflictها تشخیص داده شده اند ، حل میشوند یا به تعویق میافتد :
یک Conflict زمانی تشخیص داده میشود که ، یک نسخه تغییرات در replica شامل knowledge دیگران نباشد .
اساسا ، Conflict زمانی رخ میدهد که در دوره همگام سازی ، تغییرات بر روی یک item در دو replica انجام شود .
Destination داده Item را از source درخواست میکند :
در طول این فاز ، Destination تخمین میزند که کدام Item در source نیاز به بازیابی دارد ، آن را درخواست میکند .
Source داده های ایتم را آماده و ارسال میکند :
source درخواست item data را دریافت میکند و داده را برای ارسال به destination آماده میکند . اگر داده رهگیری شده درون یک سطر از پایگاه داده باشد ، آن سطر از پایگاه داده را ارسال میکند ، اگر داده در یک فایل باشد ، کل فایل منتقل میشود .
Item در Destination تایید میشود :
در Destination داده دریافت و تایید میشود ، اگر هر گونه خطایی در طی پردازش باشد ، item تحت عنوان یک exception علامت گذاری میشود تا در همگام سازی مرحله بعدی اصلاح شود . knowledge دریافتی از source به knowledge مقصد اضافه میشود .
مثال Synchronization :
ما مثالی را بررسی خواهیم کرد که ، چگونگی شمارش خطا و در نهایت تایید item dataها توسط Sync Framework را نشان خواهد داد .
در این مثال در replicas داریم : Replicas A و Replicas B که ، Replicas A همگام سازی را به Replicas B آغاز خواهد کرد ( این بدین معناست که Source ، Replicas A است و Destination ، Replicas B است )
برای مثال فرض کنید ما قصد همگام سازی یک فایل در بین این Replicas را داریم . یک فایل تنها درون فولدر Itemی خواهد بود که رهگیری میشود و همانند In (براي مثال , I1, I2 , I3 … ) . زمانی که یک فایل جدید (I1) ساخته میشود ، metadata همراه آن نیاز دارد که بروزرسانی شود ، داریم :

اگر این فایل دوباره بروزرسانی شده بود ، جدول versionها شبیه زیر میشود :

در اینجا چندین فایل رهگیری میشوند ، پس اجازه دهید چندین item بیاوریم . اگر توجه کنید ، خواهید فهمید که ، informationها زمانی که Itemها ایجاد میشوند ، زیاد و زیاد تر میشوند . Sync Framework نیازی به ذخیره سازی نسخه قبلی نسخه بروزرسانی ندارد .
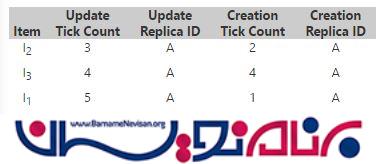
اگر ما وضعیت فعلی itemها رابرای replicas در نظر بگیریم ، ما باید Knowledge مربوط به Replicas A را همانند زیر نمایش دهیم :
Replica A Knowledge = A5
Replicas ID ، A است و 5 tick count جاری است که replicas آن را تشخیص میدهد .
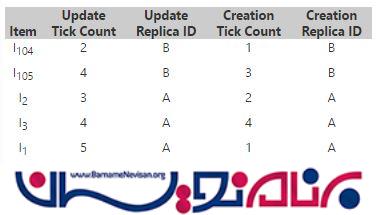
در Replicas B در اینجا ممکن است تعدادی فایل نیز وجود داشته باشد ، این Replicas شبیه زیر میشود :
Replicas B :

Knowledge جاری برای Replicas B :
Replica B Knowledge = B4
destination این نسخه ها را دریافت میکند و شمارش میکند ، برای اینکه چه کسی از source درخواست داده است را تخمین بزند . همچنین برای تشخیص Conflict نیز از این نسخه ها استفاده میکند .
حال ، Replicas A فایلهایی را که همراه I1,I2 و I3 هست را ارسال میکند .
destination فایلها را دریافت کرده و به فولدر خودشان اضافه میکند .
در آخرین قسمت از این دوره همگام سازی ، این فرآیند بیش از یکبار اجرا میشود ، با این تفاوت که جای
Source و Destination با هم عوض میشود .
در آخرین مرحله Knowledge بروزرسانی شده ی Replicas A و Replicas B همانند زیر است :
Replica A Knowledge = A5, B4
Replica B Knowledge = A5, B4
مثال Conflict :
مثال قبل را گسترش میدهیم ، هر دو replica الان همگام سازی شده اند و item version آنها همانند زیر است :
knowledge برای هر دو replica همانند زیر است :
Replica A Knowledge = A5, B4
Replica B Knowledge = A5, B4
در این نقطه ، هر دو replicas تصمیم به بروزرسانی یک فایل میکنند (item I2)
در replica A جدول item version همانند زیر میشود :
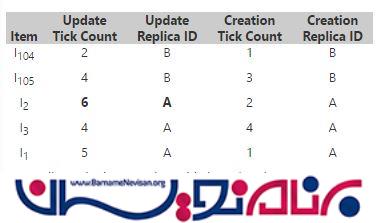
در replica A جدول item version همانند زیر میشود :
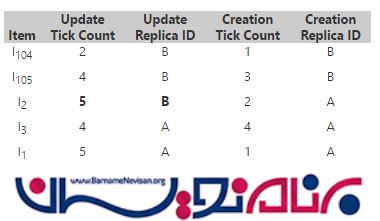
knowledge برای هر دو replica همانند زیر است :
Replica A Knowledge = A6, B4
Replica B Knowledge = A5, B5
در این نقطه Replica A همگام سازی را با Replica B آغاز میکند . به قسمتی میرویم که Source آیتم version و Knowledge را به destination ارسال میکند . مراحل زیر برای Item I2 است :


یک Conflict تشخیص داده میشود و به برنامه یا Provider برای مدیریت آن ارسال میشود .

- برنامه نویسان
- 4k بازدید
- 3 تشکر