ترکیب شیء ها با استفاده از SOLID
پنجشنبه 28 مرداد 1395این مقاله به شما نحوه ترکیب یک شی با استفاده از SOLID را نمایش میدهد که به شما در تکمیل یک برنامه کمک می کند. با به کارگیری اصول SOLID ، و به ویژه Single Responsibility Principle (SRP) ، کد ما می تواند به مجموعه بزرگی از کلاس های کوچک شکسته شود.

با به کارگیری اصول SOLID ، و به ویژه Single Responsibility Principle (SRP) ، کد ما می تواند به مجموعه بزرگی از کلاس های کوچک شکسته شود. هر کدام از این کلاس ها مسئول انجام بخش کوچکی از کار ها هستند . از ترکیب این کلاس های مجزا و کوچک در نهایت، یک برنامه پیچیده و عظیم به دست می آید .
این کلاس های کوچک باید به میزان بالایی قابل ترکیب شدن باشند تا کار ترکیب آن ها برای ما ساده تر شود و به سادگی بتوانیم رفتار پیچیده ای که برای برنامه مان انتظار داریم را از آن ها دریافت کنیم. برای این که کلاس هایی داشته باشیم که قابل ترکیب شدن باشند، باید وابستگی ها را به آن ها تزریق کنیم. (وابستگی ها نباید در درون خود کلاس ها باشند) . این وابستگی ها باید در قالب کلاس های Abstract یا Interface ها باشند. این دقیقا همان روشی است که به آن Dependency Injection (DI) یا تزریق وابستگی ها می گوییم.
برنامه Object Composition
ویژگی اصلی این برنامه، (برنامه Document Indexer) خواندن فایل های متنی از file system ، استخراج کلمات هر متن، وذخیره متن ها و کلمات در درون پایگاه داده است. اطلاعاتی مانند این موارد می توانند در کارهای بعدی برای جستجوی سریع مورد استفاده قرار بگیرند.
اگر چه ویژگی اصلی این برنامه، ساده به نظر می رسد، ما می خواهیم ویژگی های بیشتری به برنامه اضافه کنیم و آن را توسعه بدهیم. به ویژه ما می خواهیم ویژگی هایی مانند "تشخیص اسنادی که قبلا پردازش شده اند"، " نمایش اطلاعات مربوط به نحوه عملکرد برنامه"، "ذخیره تعداد اسناد پردازش شده" ، "انتقال اسناد پردازش شده به یک پوشه دیگر " ، "امکان دسترسی به پایگاه داده در زمان بروز خطا " ، "ذخیره خطاهای مربوط به دسترسی به پایگاه داده در یک گزارش " و در نهایت اجرای کامل تمامی این روندها به صورت پیوسته و مستمر است.
تمامی تمرکز ما در این مقاله بر روی مسئله "object composition" است و از پرداختن به مسائلی مانند تست پروژه، الگوهای مربوط به دسترسی به داده ها و ساختار کلی پروژه صرف نظر کرده ایم.
آدرس مربوط به این مطالب بر روی object composition عبارت است از :
https://github.com/ymassad/CompositionExample
ساختار ابتدایی
شما می توانید نسخه ابتدایی برنامه را با استفاده از آدرس زیر پیدا کنید:
https://github.com/ymassad/CompositionExample/tree/InitialApplication
برای این که بتوانید این برنامه را اجرا کنید، باید امور زیر را انجام بدهید:
1- ابتدا مطمئن شوید که برنامه SQL Server بر روی سیستم شما نصب باشد.
2- پوشه Documents که در repository قرار دارد را در محل file system خود کپی کنید. این پوشه حاوی 100 سند نمونه است.
3-فایل solution را با Visual Studio باز کنید. برای ساخت این فایل ما از نسخه 2015 ویزوال استودیو استفاده کرده ایم، ولی با نسخه 2013 نیز به خوبی کار می کند.
4-Settings.Xml را باز کنید، مقدار المان ConnectionString را به گونه ای تنظیم کنید که با تنظیمات برنامه SQL server شما هماهنگ باشد.
5-در Settings.Xml ، مقدار المان FolderPath را برابر با آدرسی که می خواهید فایل ها را در آن قرار بدهید، بگذارید.
6-solution را یک بار Build کنید و برنامه را اجرا کنید.
حالا برنامه را دانلود کنید، نگاهی به کدهای آن بیندازید . یکی از بخش های مهم Composition Root در Program.cs است که حتما باید به آن نگاه کنید.
تصویر زیر object graph را نشان می دهد که در Composition Root وجود دارد:
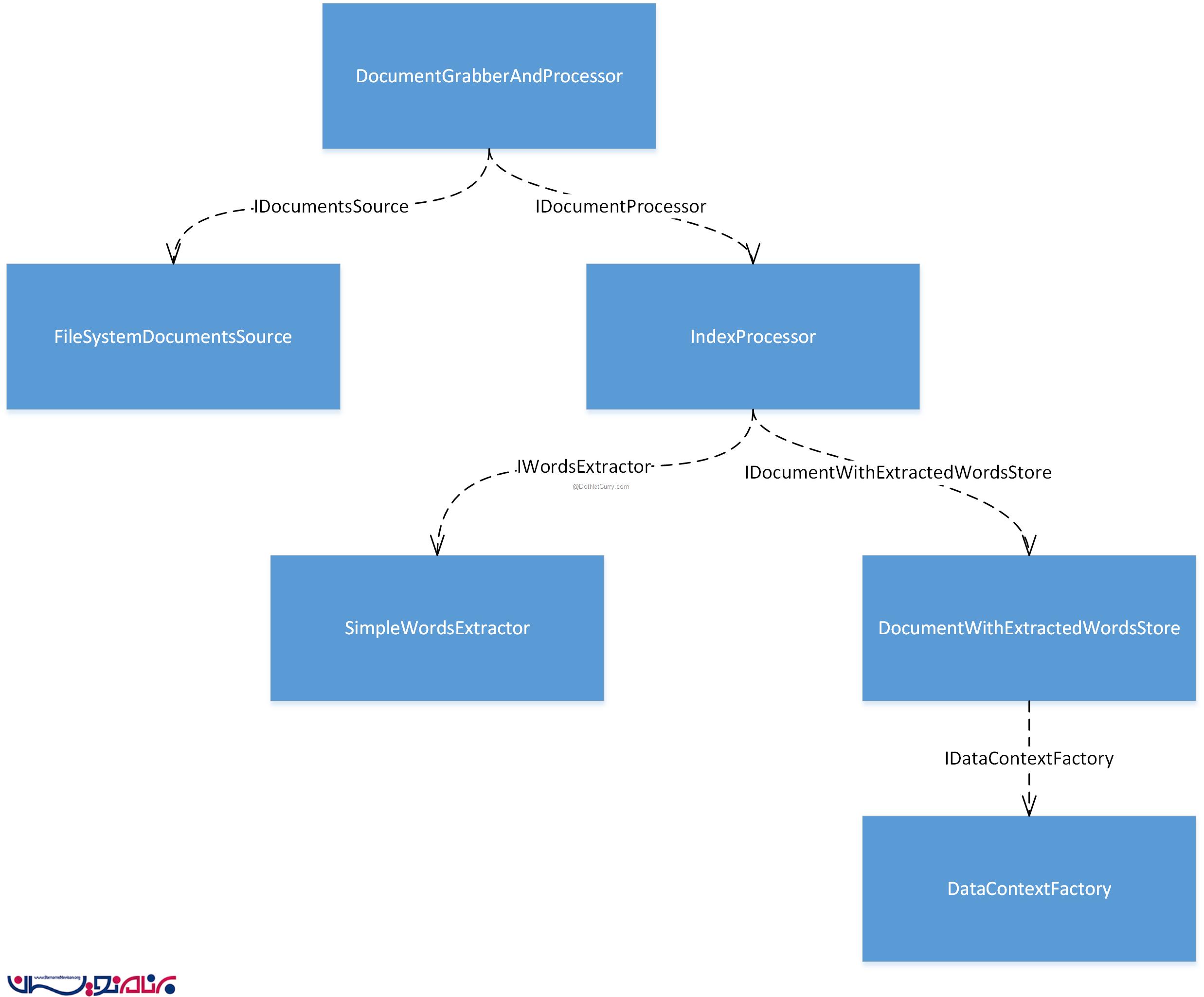
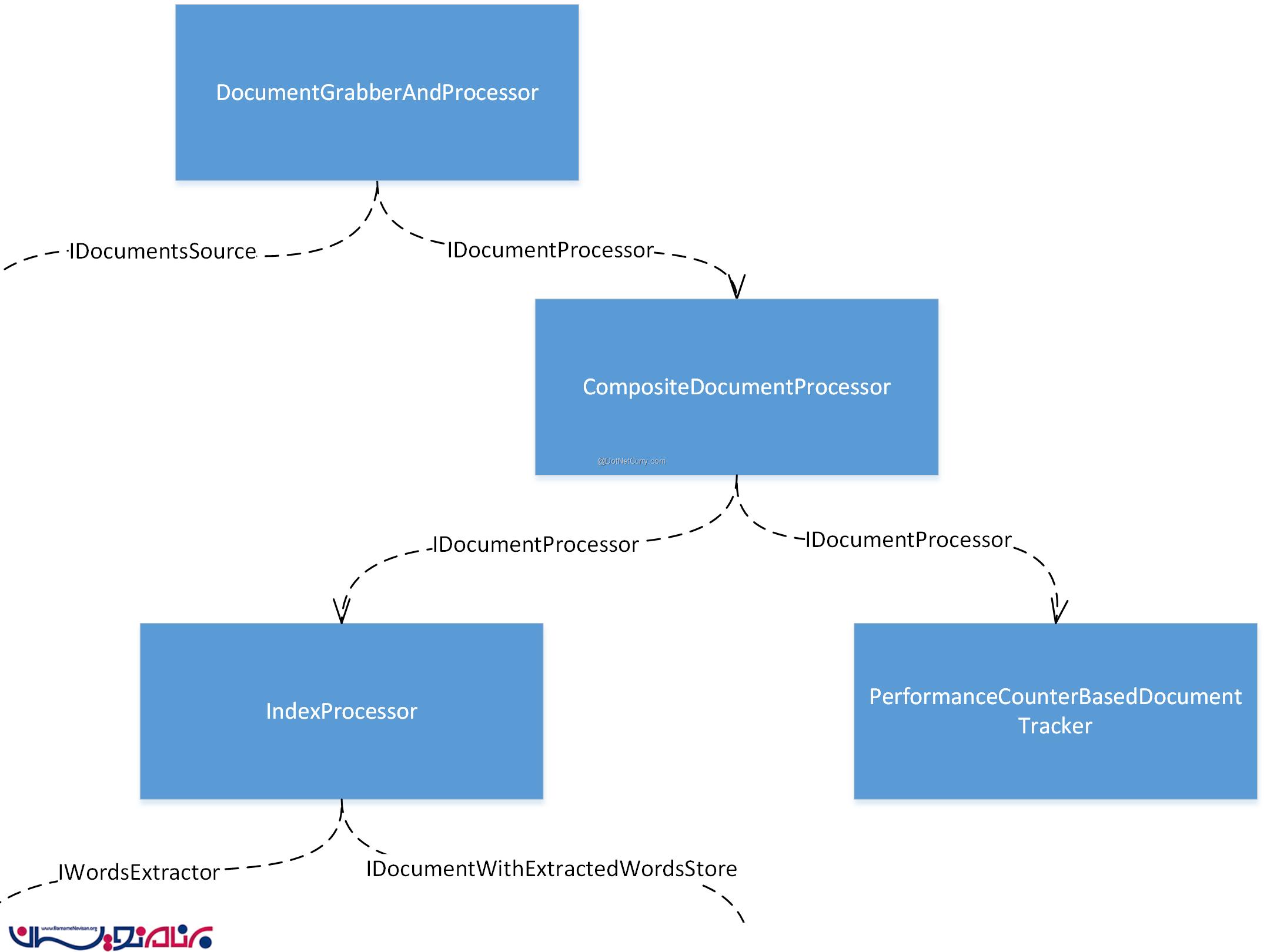
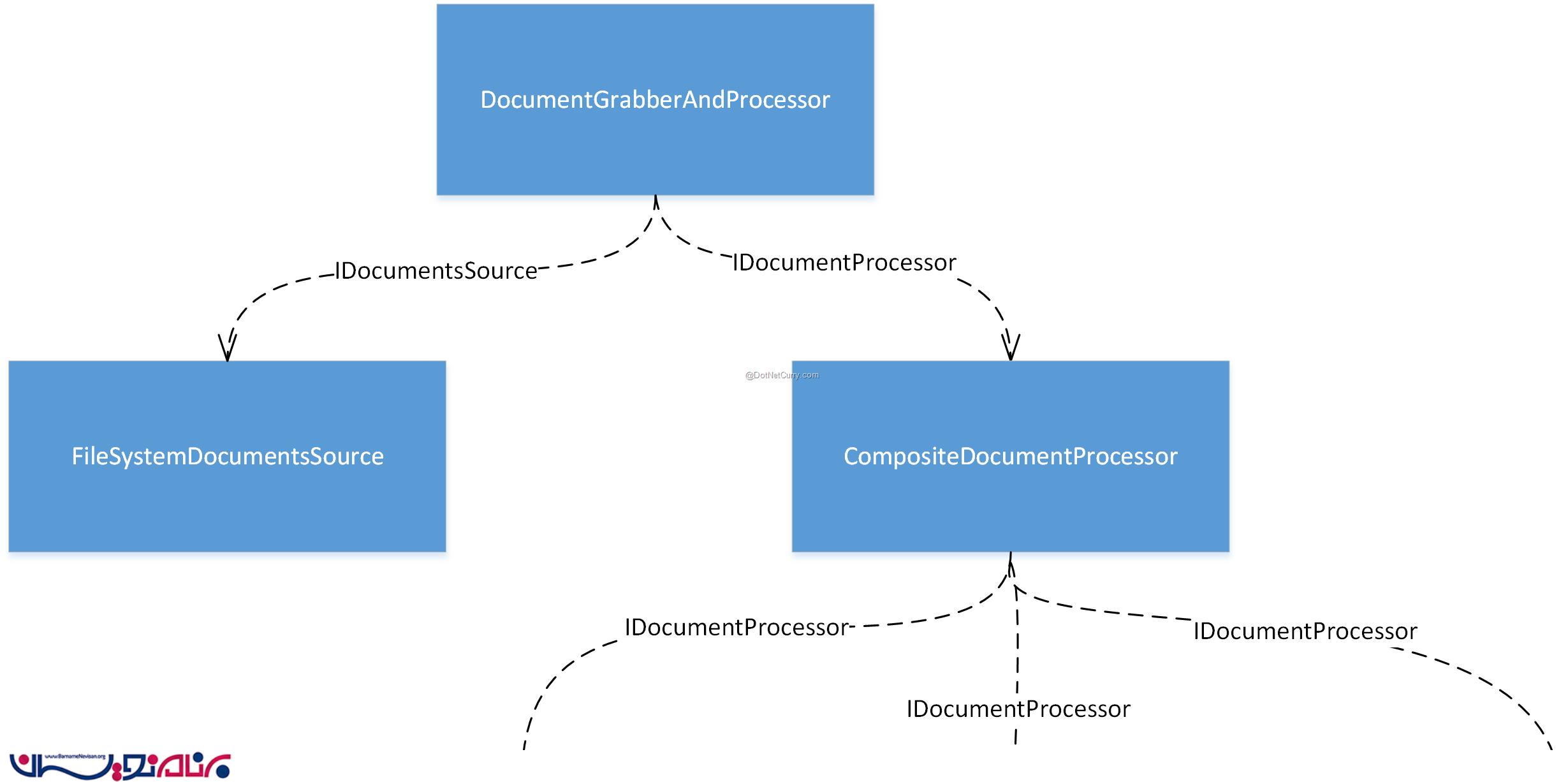
شی DocumentGrabberAndProcessor شی اصلی است، و اینترفیس IRunnable را پیاده سازی می کند ، به همین خاطر به این وسیله می تواند وظایفش را انجام بدهد. همچنین می تواند از وابستگی IDocumentsSource برای شناسایی اسناد و ارسال آن ها به بخش IDocumentProcessor جهت بررسی، استفاده می کند.
در حال حاضر، ما یک FileSystemDocumentsSource داریم که اسناد را از file system دریافت می کند. برای IDocumentProcessor ما یک کلاس IndexProcessor داریم که با استفاده از وابستگی IWordsExtractor کلمات را از اسناد استخراج می کند و سپس از وابستگی IDocumentWithExtractedWordsStore برای ذخیره اسناد و کلمات استخراج شده استفاده می کند.
با استفاده از این اینترفیس ها، ما به سیستم ، قابلیت ویرایش شدن داده ایم. این اینترفیس ها، نقاط توسعه ما هستند. در بخش بعدی، ما از این نقاط توسعه برای افزودن قابلیت های جدید به سیستم استفاده خواهیم کرد. حالا بیایید برنامه را اجرا کنیم.
بعد از اجرای برنامه، یک پایگاه داده جدید به نام DocumentIndexer در SQL Server ایجاد خواهد شد. در این پایگاه داده شما دو جدول خواهید داشت که نام های آن ها عبارتند از Documents و IndexEntries.
هر سطر در جدول Documents شامل نام سند و محتویات آن سند خواهد بود. برای هر کلمه مجزا در یک سند مجزا ، یک سطر در جدول IndexEntries در نظر گرفته می شود و اطلاعات مربوطه در آن سطر قرار می گیرند.
یکی از ویژگی هایی که به آن نیاز داریم عبارت است از : برنامه ما باید از سندی که در حال پردازش است، اطلاع داشته باشد.
روندی که برنامه در حال حاضر دارد به این صورت است که همه اسناد را می گیرد، پردازش می کند و سپس اطلاعات مربوط به آن ها را در پایگاه داده ذخیره می کند، حتی اگر این اسناد قبلا مورد پردازش قرار گرفته باشند.
ما نیاز داریم تا این رفتار سیستم را به گونه ای تغییر بدهیم تا اسناد پردازش شده را از اسنادی که تا به حال پردازش نشده اند، جدا کند. چه ویژگی ای به ما امکان تزریق این رفتار به برنامه را می دهد؟
ما در این جا دو گزینه داریم: ما می توانیم یک decorator برای IDocumentsSource ایجاد کنیم که اسناد پردازش شده را فیلتر کند و یا می توانیم یک IDocumentProcessor ایجاد کنیم که از اسنادی که قبلا پردازش شده اند، عبور کند و دوباره آن ها را مورد پردازش قرار ندهد.
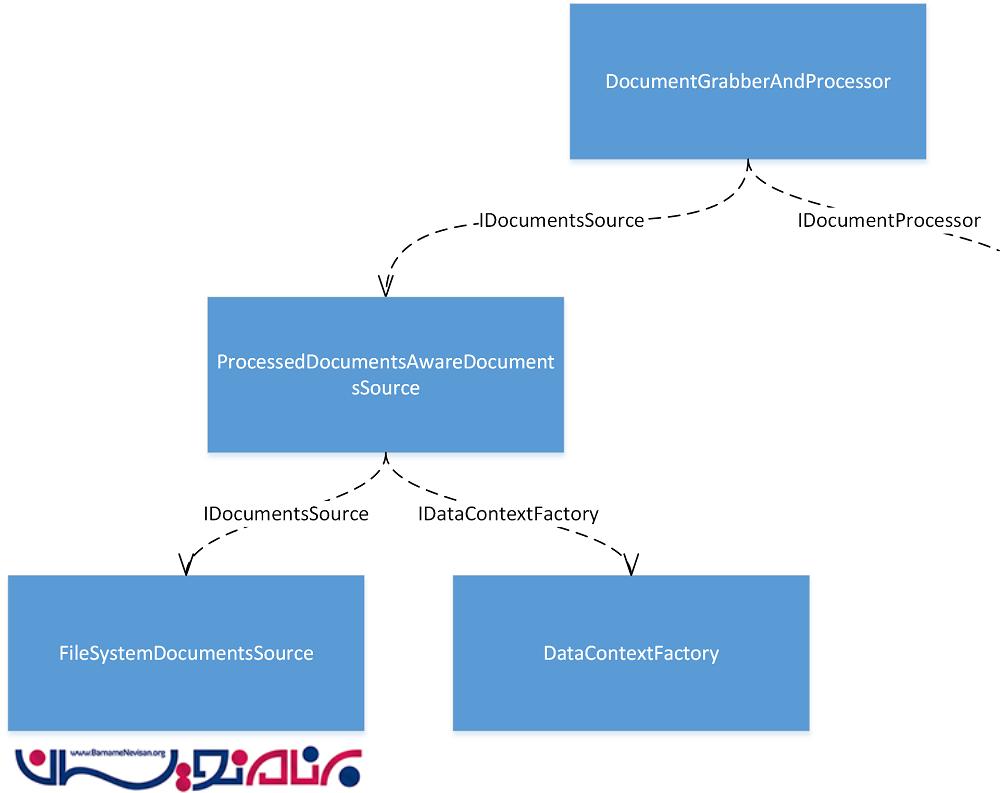
ما یک decorator برای IDocumentsSource ایجاد خواهیم کرد که با پایگاه داده ارتباط برقرار می کند و اسنادی که تا به حال پردازش شده اند را قبل از ارسال خروجی ها به کاربر، فلیتر می کند و نام آن را ProcessedDocumentsAwareDocumentsSource می گذاریم. بخشی از object graph که مربوط به این بخش است، به صورت زیر می باشد:
نکته ای درباره کارایی و راندمان برنامه
شما ممکن است توجه کرده باشید solution ای که ما در بالا از آن استفاده کرده ایم، کمی در رابطه با کارایی و راندمان مشکل دارد. یکی از راه حل های این موضوع این است که FileSystemDocumentsSource را به گونه ای به بخش های مختلف تقسیم کنیم که یکی از بخش ها مسئول شناسایی فایل ها (دریافت نام فایل ها ) و دیگری مسئول خواندن فایل ها باشد(دریافت محتویات). وظیفه شناسایی فایل ها می تواند به اینترفس دیگری منتقل شود که می توانیم بعدا آن را تنظیم کنیم تا بتواند فایل هایی که قبلا پردازش شده اند را فیلتر کند.
در این مقاله، ما بر روی نمایش میزان قدرت و توانایی object composition تمرکز کرده ایم ، بنابراین نمی خواهیم دستکاری های زیادی بر روی فایل ها انجام بدهیم. در مراحل بعدی این مقاله ما پوشه ای می سازیم و اسناد پردازش شده را در آن قرار می دهیم و به این صورت مشکل را حل می کنیم.
گام بعدی : ما نیاز داریم تا مدت زمان لازم برای ذخیره یک سند در پایگاه داده را به دست بیاوریم.
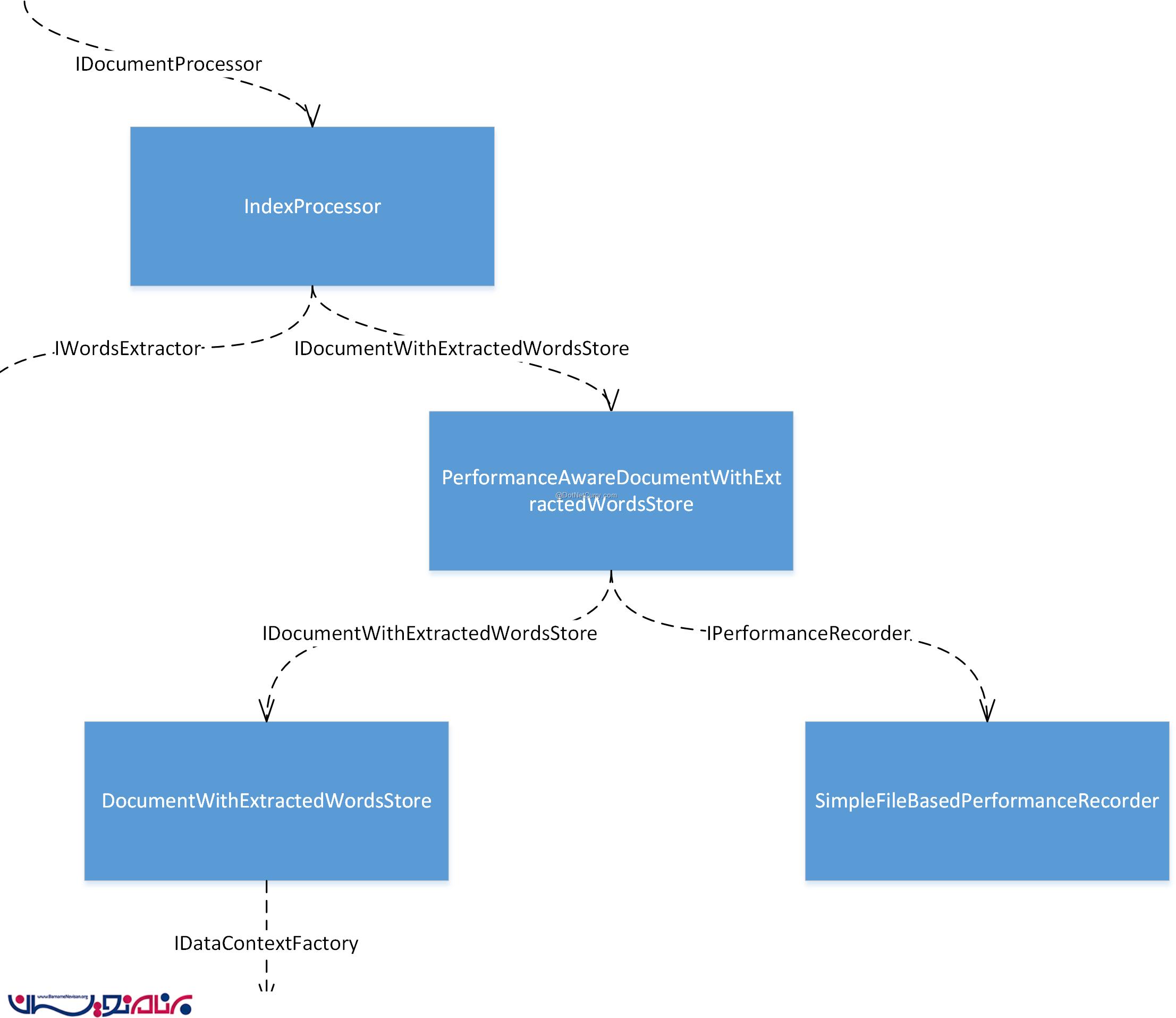
در این ویژگی ، ما نیاز داریم تا درخواست هایی که برای ذخیره اسناد در پایگاه داده صورت می گیرد را ضبط و بررسی کنیم، زمان آن ها را اندازه گیری کنیم و این اطلاعات را در یک محل ذخیره کنیم. برای این مرحله، ما به سادگی این اطلاعات را در درون یک فایل متنی ذخیره می کنیم.
ما یک decorator برای IDocumentWithExtractedWordsStore ایجاد خواهیم کرد که زمان ذخیره یک سند در پایگاه داده را اندازه بگیرد و سپس یک وابستگی به نام IPerformanceRecorder را تزریق می کنیم تا زمان را ذخیره کند. تا این مرحله، ما یک IPerformanceRecorder را پیاده سازی می کنیم تا بتواند زمان ها را در خطوط جداگانه در یک فایل متنی وارد کند. در زیر object graph مربوط به این بخش نمایش داده شده است :
به روز رسانی یک بخش از برنامه : زمان را به جای این که در یک فایل متنی ذخیره کنیم،در یک Performance Counter ذخیره نماییم.
product owner به ما می گوید که نگهداری زمان در یک فایل متنی قابل قبول نیست زیرا مدیریت آن کار سختی است . بنابراین ما تصمیم گرفتیم که از یک Performance Counter (شمارنده ی راندمان ) برای ذخیره سازی زمان استفاده کنیم . و به صورت ویژه تر ، ما تصمیم گرفتیم تا زمان متوسط ذخیره یک سند در پایگاه داده را ذخیره کنیم.
Performance Counter (شمارنده های راندمان ) در سیستم عامل ویندوز ، شی هایی هستند که ما می توانیم برای ذخیره ی اطلاعات مربوط به راندمان از آن ها استفاده کنیم.
ما در حال حاضر یک Interfaceبه نام IPerformanceRecorder داریم . مواردی که در این مرحله نیاز داریم ، ایجاد یک پیاده سازی از این interface است که برخی از Performance Counter ها را در خودش نگهداری کند، و سپس بتوانیم یک نمونه از کلاس جدید را در یک مکان مناسب در قالب یک وابستگی به آن تزریق کنیم. برخی از object graph که مربوط به این بخش است، به صورت زیر می باشد:
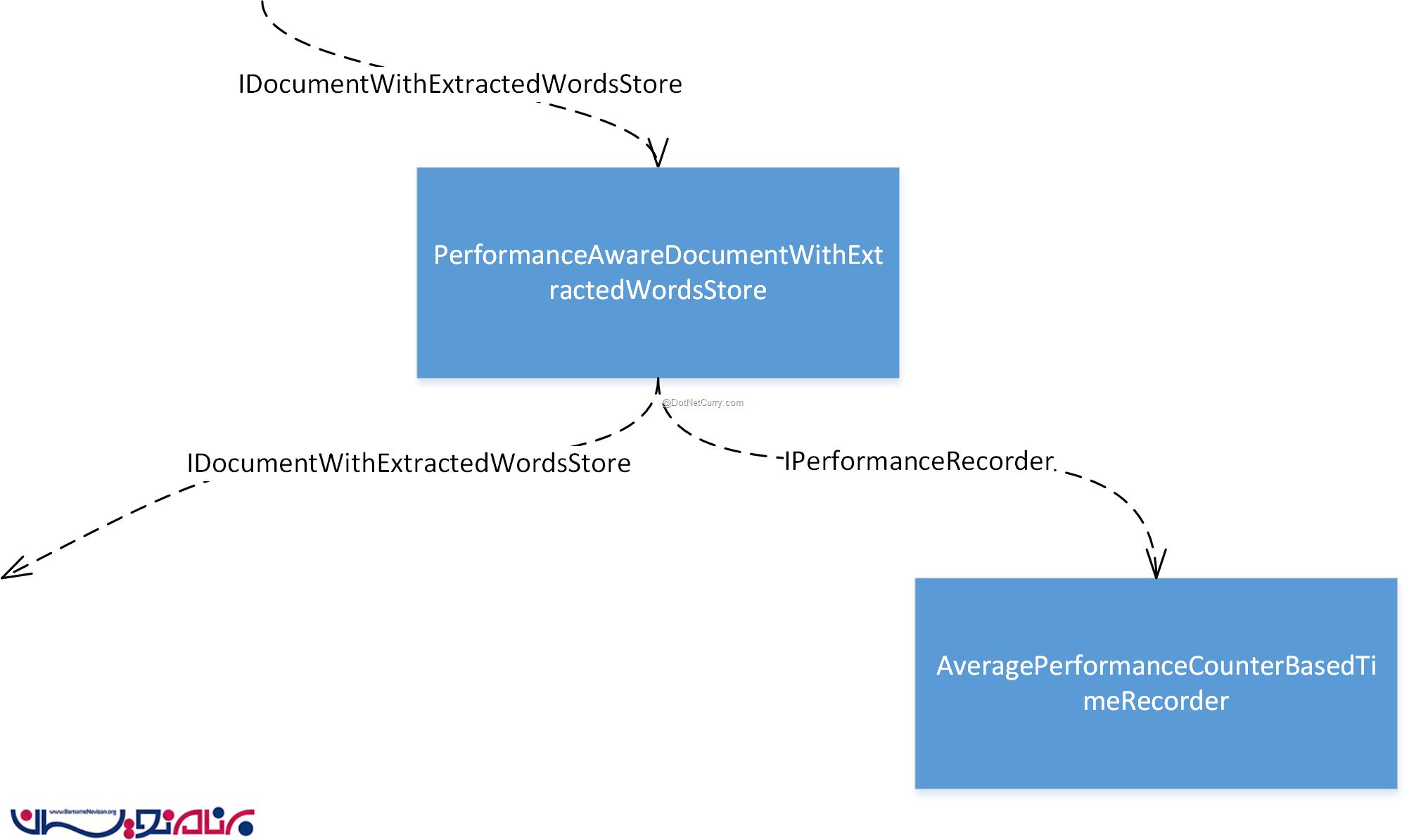
ما به آسانی کلاس AveragePerformanceCounterBasedTimeRecorder را ایجاد کرده و یک نمونه را در قالب یک وابستگی به آن تزریق کرده ایم تا بتوانیم مانند گذشته از نمونه SimpleFileBasedPerformanceRecorder استفاده کنیم.
لطفا توجه کنید که ما یک متد به نام EnsurePerformanceCountersAreCreated ایجاد کرده ایم که آن را در شروع برنامه فراخوانی می کنیم. این متد ، Performance Counter ها را در سطح سیستم عامل ایجاد می کند. معمولا این بخش از کدها در installation wizard و یا deployment script ها قرار می گیرند، دلیل این که آن را در این محل قرار دادیم این است که شما به سادگی بتوانید این مثال را اجرا کنید.
همچنین به این نکته نیز توجه داشته باشید که برای دسترسی به Performance Counter ها ، شما باید administrator و یا Performance Monitor Users group باشید.
گام بعدی : ما باید تعداد اسناد پردازش شده را در یک Performance Counter ذخیره کنیم.
در این مرحله ما نیاز داریم تا تعداد اسناد پردازش شده را در یک Performance Counter ذخیره کنیم. اما موضوع مهم این جاست که ما تزریق این بخش را در چه محلی باید انجام دهیم؟
اینطور به نظر می رسد که ما نیاز داریم در اینترفیس IDocumentProcessor در object graph تغییراتی ایجاد کنیم. ما می توانیم از composite pattern برای ایجاد یک document processor (پردازشگر متن) استفاده کنیم که از دو پردازشگر و یا بیشتر استفاده می کند. ما می توانیم از آن برای فراخوانی پردازشگر متن جاری خودمان استفاده کنیم. به عنوان مثال IndexProcessor و یک پردازشگر جدید که فقط مقدار Performance Counter را هر بار، یک واحد اضافه کند. object graph مربوط به این بخش به صورت زیر خواهد بود:
گام بعدی : انتقال اسناد پردازش شده به یک پوشه جدید
زمانی که پردازش یک سند به طور کامل به اتمام برسد، ما باید آن را به یک پوشه جدید منتقل کنیم. برای انجام این کار، باید به سادگی یک implementation جدید از IDocumentProcessor ایجاد کنیم (به نام DocumentMover) که اسناد را به برخی از پوشه ها انتقال بدهد. سپس این مورد را به عنوان یک پردازشگر سند مجزا به نمونه ی CompositeDocumentProcessor اضافه می کنیم . بخشی از object graph مربوط به این توضیحات، در زیر آورده شده است :
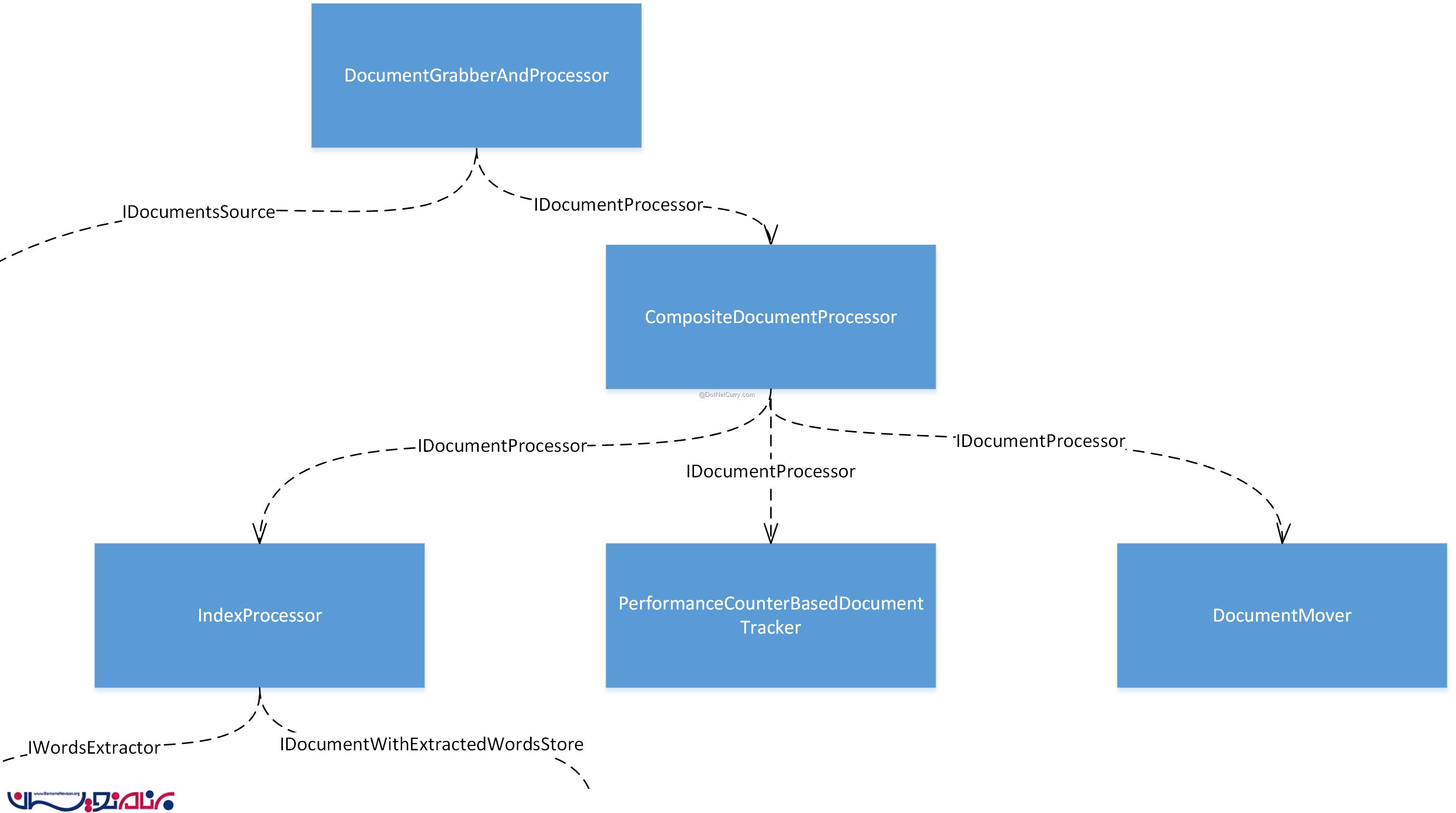
حالا به این دلیل که ما داریم فایل های پردازش شده را به یک پوشه جداگانه انتقال می دهیم، دیگر نیازی به بررسی اسناد موجود در پوشه اصلی نداریم (برای چک کردن این که بررسی شده اند یا نه ) . بنابراین ما نمونه ی ProcessedDocumentsAwareDocumentsSource را از object graph حذف می کنیم. بخش مربوط به این تغییر در زیر آورده شده است :
گام بعدی : ما نیاز داریم روند ذخیره سازی اسناد در پایگاه داده را در صورت بروز خطا در پایگاه داده ، دوباره تکرار کنیم.
برخی اوقات زمانی که ما در حال تلاش برای ذخیره یک سند هستیم، عملیات با شکست روبرو می شود و ما با یک خطا مواجه می شویم. در برخی موارد، دلیل این خطا، موقتی و گذرا است . کاری که ما باید در این موارد انجام بدهیم این است که دوباره ذخیره سازی سند را انجام بدهیم. به عنوان مثال می توانیم پنج بار تلاش برای ذخیره سازی را تکرار کنیم.
ما در این مرحله می خواهیم یک decorator برای IDocumentWithExtractedWordsStore ایجاد کنیم تا بتواند متد مربوط به ذخیره سازی سند را چندین بار تکرار کند. ما فعلا این decorator را RetryAwareDocumentWithExtractedWordsStore می نامیم. ما برای این که بتوانیم استراتژی های مختلفی برای تزریق استفاده کنیم نیاز داریم تا این کلاس را به اینترفیس IRetryWaiter وابسته کنیم. implementation جاری از IRetryWaiter ، IncrementalTimeRetryWaiter زمان انتظار را به وسیله یک مقدار ثابت، هر بار اضافه می کند.
بخشی از object graph مربوط به این توضیحات به صورت زیر خواهد بود :
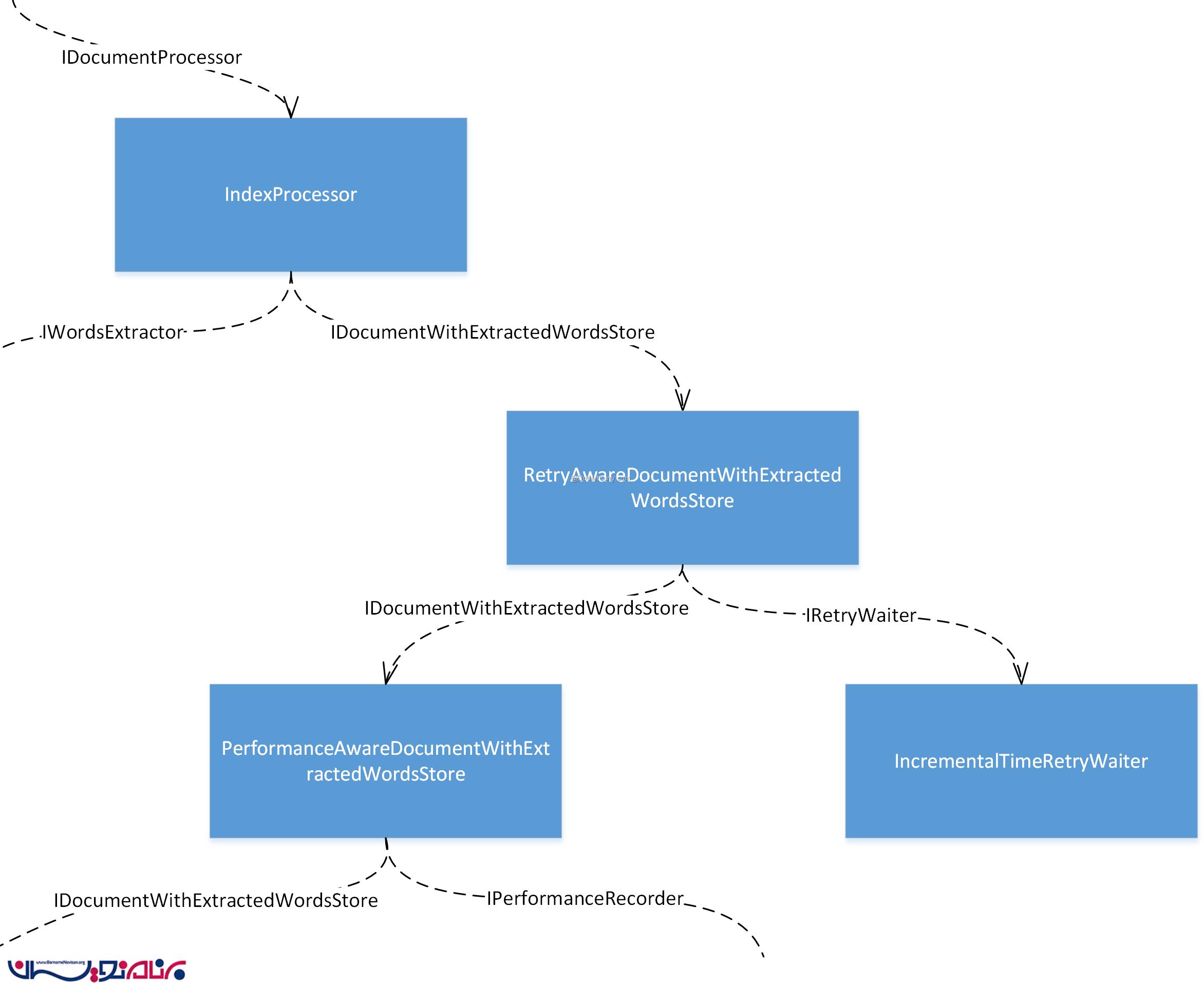
ببینید که ما چگونه یک نمونه از کلاس جدید را در بالای شی PerformanceAwareDocumentWithExtractedWordsStore تزریق کرده ایم . (تا به منزله ی یک decorator برای آن باشد.). ما می توانیم این کار را با روش های دیگری نیز انجام بدهیم. این تغییر را می توانید در تصویر زیر ببینید :
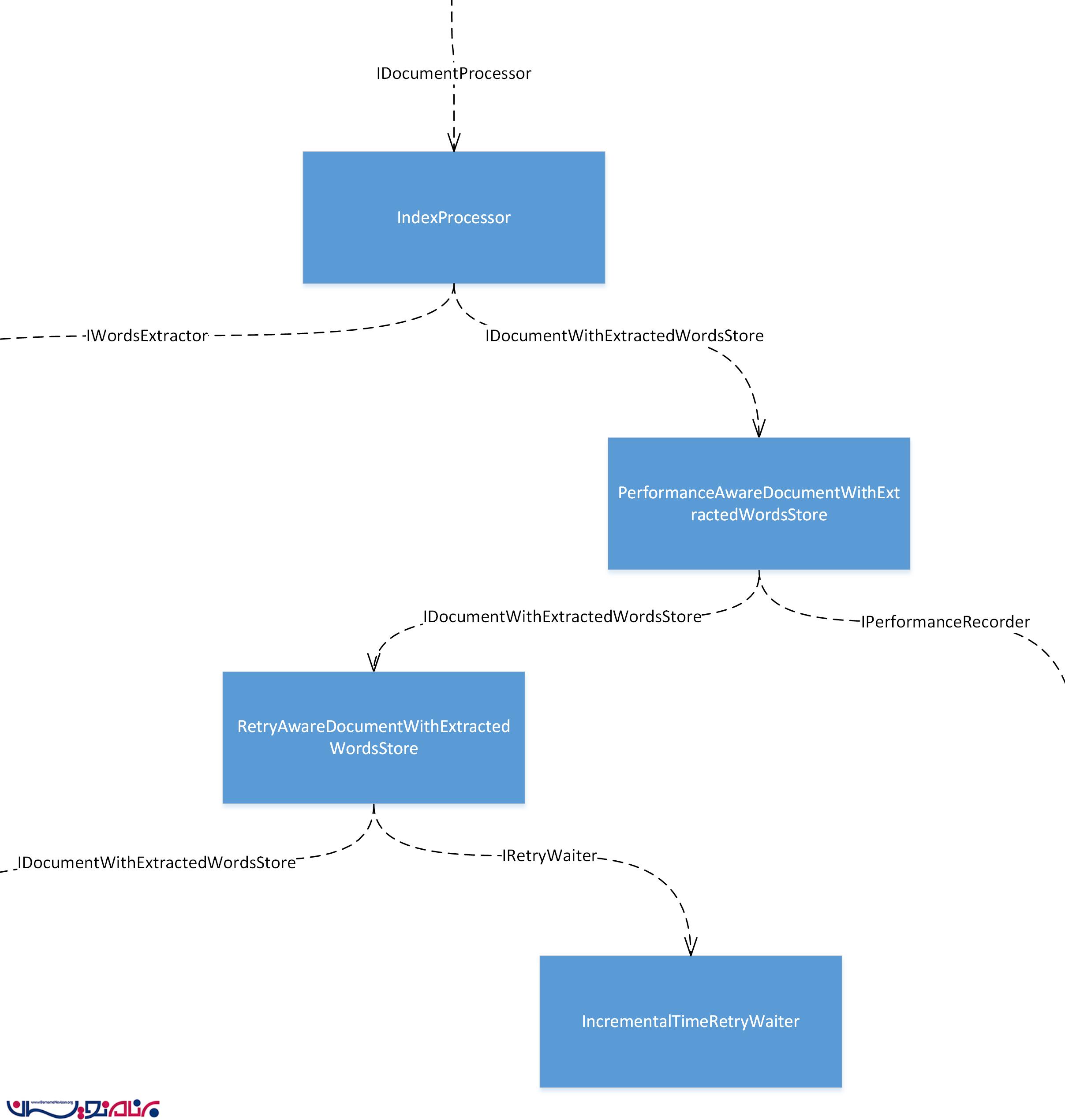
تفاوت این دو چیست؟ کمی راجع به این موضوع فکر کنید.
تفاوت اصلی این است که در مورد اول، زمان اندازه گیری شده (در to the Performance Counter) برای یک بار تلاش موفق ذخیره سازی سند در داخل پایگاه داده است (که این، دقیقا همان چیزی است که مد نظر ما است). در مورد دوم ، زمان اندازه گیری شده ، کل زمانی است که ما برای ذخیره سازی موفق یک سند در داخل پایگاه داده صرف کرده ایم، که شامل زمان هایی که تلاش ها ناموفق بوده اند، نیز می شود.
این یک مثال ساده و آشکار است که چگونه تفاوت در به کارگیری و تزریق شی ها، موجب تغییر رفتار برنامه می شود.
گام بعدی : ما باید خطاهایی که در زمان ذخیره سازی سند در پایگاه داده اتفاق می افتند را در یک گزارش وارد نماییم.
تلاش دوباره برای عملیات ذخیره سازی سند در داخل پایگاه داده کافی نیست، ما نیاز داریم تا خطاهایی که اتفاق می افتد را در یک فایل گزارش وارد نماییم.
این کار ساده است. ما یک decorator دیگر برای IDocumentWithExtractedWordsStore نیاز داریم.
ما کلاس ErrorAwareDocumentWithExtractedWordsStore را ایجاد می کنیم و آن را به مکان مناسب تزریق می کنیم. بخش مربوط به این کار به صورت زیر خواهد بود :
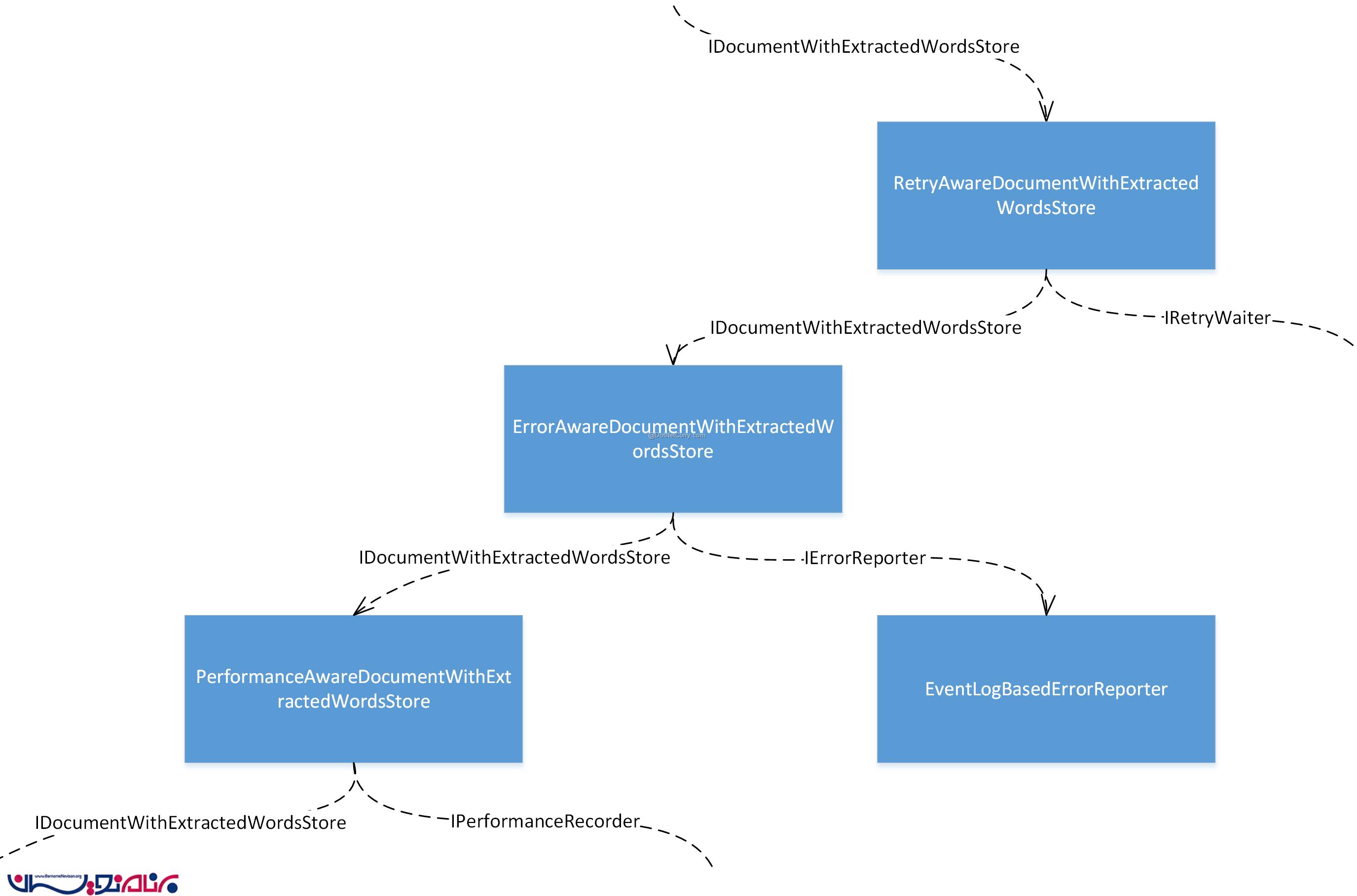
توجه داشته باشید که کلاس ErrorAwareDocumentWithExtractedWordsStore یک وابستگی به IErrorReporter دارد. این وابستگی به ما اجازه می دهد تا به صورت های مختلفی بتوانیم خطاها را گزارش کنیم. در این مقاله ما یک implementation از IErrorReporter داریم که خطاها را در درون یک Event Log برای ما می نویسد.
لطفا توجه داشته باشید که کد، یک event log source به نام DocumentIndexer ایجاد خواهد کرد. برای این کار، شما نیاز به دسترسی در سطح administrator دارید.
گام بعدی : ما نیاز داریم برنامه تا زمانی که در حال اجرا است، اسناد جدید را واکشی کند
در حال حاضر، برنامه، یک بار اسناد را از داخل پوشه برمیدارد، پردازش می کند و سپس خارج می شود. کاری که ما می خواهیم بکنیم این است که برنامه در طول زمان اجرا، گرفتن اسناد جدید را ادامه بدهد و تا زمانی که کاربر دستور خروج نداده است، به این کار ادامه بدهد.
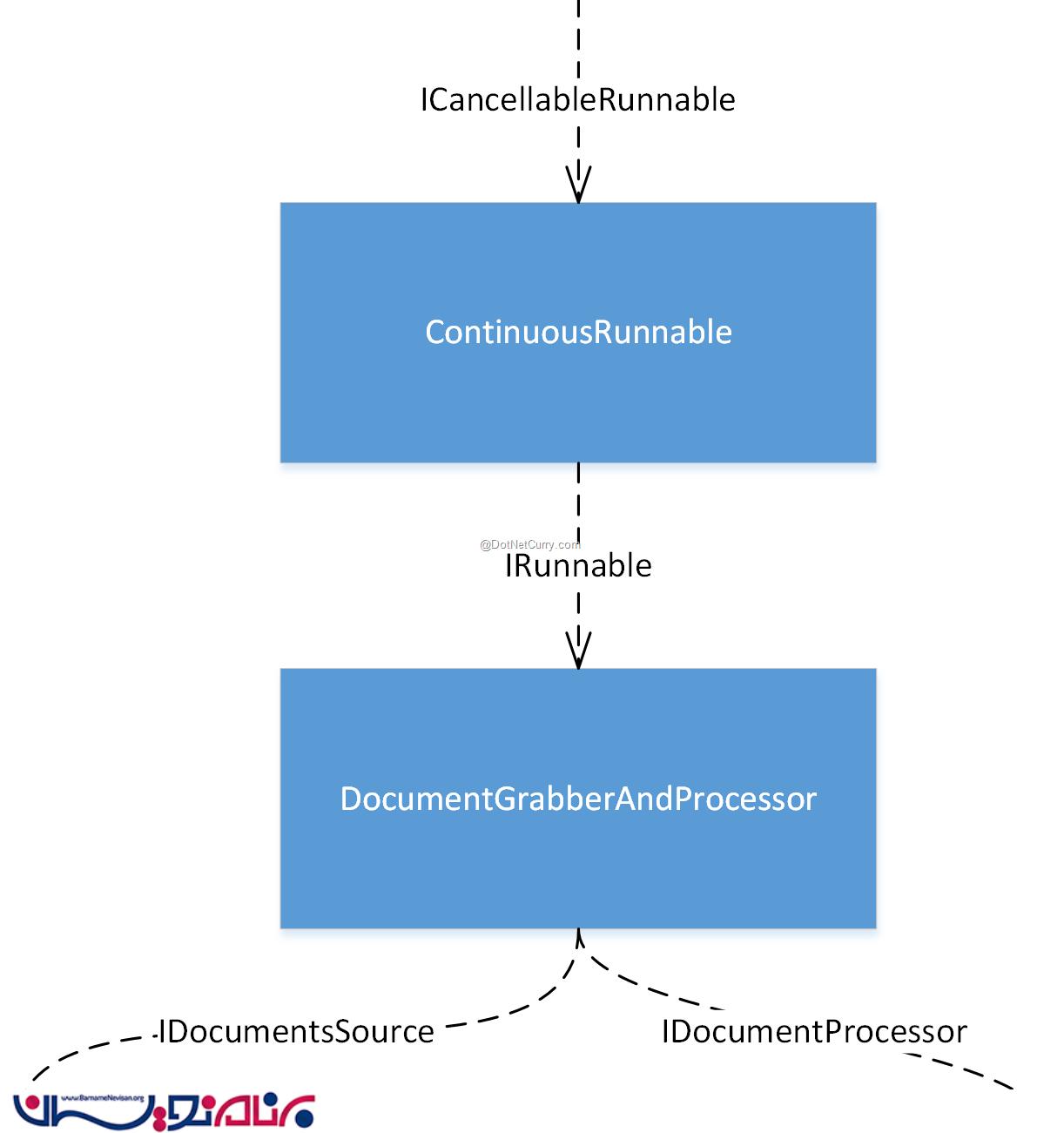
ما یک اینترفیس جدید به نام ICancellableRunnable ایجاد کرده ایم که به عملیات، اجازه اجرا شدن می دهد اما همچنین می تواند از توقف عملیات با استفاده از یک CancellationToken نیز، پشتیبانی کند . سپس ما یک کلاس ContinuousRunnable ایجاد کرده ایم که یک وابستگی از IRunnable را در خودش استفاده می کند . (این کار را تا زمانی ادامه می دهد که درخواست کنسل کردن عملیات صادر نشده باشد.)
این بخش از object graph ، مطالب این قسمت را به نمایش می گذارد:
خلاصه :
زمانی که ما به روش SOLID کدنویسی می کنیم، تعداد زیادی کلاس کوچک ایجاد می کنیم که هرکدام یک وظیفه مجزا در اختیار دارند. ما یک برنامه ایجاد می کنیم که از تمامی این کلاس ها با روش خاصی استفاده می کند و در نهایت، هدف مورد نظر ما را برآورده می کند. این کلاس ها به جای این که از انواع خاصی پیروی کنند، بر اینترفیس ها مبتنی هستند و به همین خاطر ، قابلیت ها و امکانات بسیاری را در اختیار ما می گذارند.

- C#.net
- 2k بازدید
- 1 تشکر