بررسی معماری سایت Stack Overflow
سه شنبه 16 شهریور 1395در این مقاله ، به بررسی اجمالی معماری سایت Stack Overflow و سخت افزارهای مرتبط با آن می پردازیم. تمامی موارد به صورت کامل ، بررسی و تحلیل شده اند تا بتوانیم دید دقیق و کاملی از این سایت محبوب به شما ارائه بدهیم.

برای به دست آوردن یک دید کلی درباره این که همه اجزا در این سایت به چه صورت کار می کنند، بیایید با بررسی بخشی از به روز رسانی های سایت Stack Overflow شروع کنیم. در زیر آماری را مشاهده می کنید که مربوط به 12 نوامبر 2013 تا 9 فوریه 2016 می باشد:
: 209,420,973 (+61,336,090)درخواست های Http که به load balancer ها فرستاده می شوند.
: 66,294,789 (+30,199,477) صفحاتی که بارگذاری می شوند.
: 1,240,266,346,053 (+406,273,363,426) بایت (1.4) ترابایت، میزان ترافیک Http است که فرستاده می شود.
: 569,449,470,023 (+282,874,825,991) بایت (569 گیگابایت) میزان کل بایت های دریافتی است.
: 3,084,303,599,266 (+1,958,311,041,954) بایت (3.08 ترابابت) میزان کل بایت های ارسالی است .
: 504,816,843 (+170,244,740) کوئری SQL که بر روی سایت زده می شود. (فقط از طریق درخواست های Http)
: 5,831,683,114 (+5,418,818,063) میزانRedis hit ها
: 17,158,874 (not tracked in 2013) جستجوی Elastic
: 3,661,134 (+57,716) درخواست های از طریق Tag
: 607,073,066 (+48,848,481) میلی ثانیه که صرف اجرای کوئری های SQl می شود.
: 10,396,073 (-88,950,843) میلی ثانیه که صرف Redis hit ها می شود.
: 147,018,571 (+14,634,512) ms (40.8 hours) میلی ثانیه که صرف درخواست های از طریق Tag ها می شود.
: 1,609,944,301 (-1,118,232,744) میلی ثانیه که صرف پردازش ها در ASP.net می شود.
: 22.71 (-5.29) میلی ثانیه( 19.12 میلی ثانیه در ASP.Net )برای 49,180,275 درخواست های بارگذاری و نمایش صفحه
11.80 (-53.2) میلی ثانیه 8.81( میلی ثانیه در ASP.Net ) برای 6,370,076 درخواست های بارگذاری صفحه اصلی
شاید کاهش قابل توجه زمان پردازش سیستم در مقایسه با سال 2013 نظر شما را جلب کرده باشد، و این در حالی است که تعداد درخواست ها نسبت به آن سال، 61 میلیون افزایش داشته است. این موضوع به دو دلیل اتفاق افتاده است که یکی از آن ها ارتقای سخت افزار سیستم در اوایل سال 2015 است .
بنابراین تغییرات این دو سال اخیر سیستم چه بوده است؟ بجز جایگزینی های تعدادی سرور و مجهز کردن شبکه ها ، کار دیگری انجام نشده است. برخی از برترین سخت افزارهای سیستم که سایت، امروزه بر روی آن ها در حال اجراست، در زیر آورده شده اند: (به تغییرات آن نسبت به سال 2013 توجه کنید ):
4 عدد Microsoft SQL Server (که سخت افزار مربوط به 2 تا از آن ها، جدید است)
11 عدد IIS Web Server (که سخت افزار مربوط به آن ها به تازگی ، جدید خریداری شده است)
2 عدد Redis Server (که سخت افزار مربوط به آن ها به تازگی ، جدید خریداری شده است)
3 عدد Tag Engine server (که سخت افزار مربوط به 2 تا از آن ها، جدید است)
3 عدد Elasticsearch server (همان سیستم های 2013 هستند )
4 عدد HAProxy Load Balancer (که 2 تا از آن ها برای پشتیبانی از CloudFlare اضافه شده اند.)
2 عدد شبکه (که هر کدام یک Nexus 5596 Core + 2232TM Fabric Extenders دارند که تا 10Gbps ارتقا داده شده اند.)
2 عدد فایروال Fortinet 800C (که با Cisco 5525-X ASAs جایگزین شده اند.)
2 عدد روتر Cisco ASR-1001 (که با Cisco 3945 Routerجایگزین شده اند.)
2 عدد روتر Cisco ASR-1001-x (که جدید هستند.)
برای راه اندازی Stack Overflow به چه چیزی نیاز داریم؟ این سایت از سال 2013 تغییر چندانی نکرده است، اما به دلیل مسائل مربوط به بهینه سازی و سخت افزار های جدیدی که در بالا به آن ها اشاره کردیم، ما در اولین مرحله کار، سطح نیازمان را تا 1 سرور ضروری کاهش داده بودیم. ما قبلا این مورد را چندین بار بر روی سیستم تست کرده ایم که فقط در چند مورد محدود، موفقیت آمیز بوده است.
حالا که ایده هایی درباره مقیاس و میزان بزرگی سایت در ذهن مان ایجاد شده است، بیایید به چگونگی ساخت این صفحه های وب زیبا بپردازیم. به این دلیل که بخش های زیادی از سیستم در محیط کاملا پوشیده و ایزوله ایجاد شده اند، تصمیمات مربوط به معماری و سازگاری قطعات با یکدیگر، تصمیمات چندان راحتی نیستند و باید به دقت گرفته شوند. هدف ما در اینجا این است که ابتدا کارهایی با مقیاس بالا را تحت پوشش خودمان قرار بدهیم. در این مقاله یک بررسی اجمالی از لحاظ منطقی بر روی نکات و تجهیزات سخت افزاری خواهیم داشت .
برای این که بتوانید ببینید دقیقا تجهیزات سخت افزاری به چه صورت هستند، تصویر زیر آورده شده است که rack A را نمایش می دهد. (که یک نمونه مشابه به نام rack B نیز دارد.)


اگر می خواهید تصاویر بیشتری را در این زمینه ببینید، می توانید این آلبوم را مشاهده کنید. حالا بیایید به سراغ بررسی بخش های مختلف برویم . در زیر یک تصویر کلی منطقی از سیستم اصلی ای که در حال حاضر بر روی سایت فعال است را می بینید:
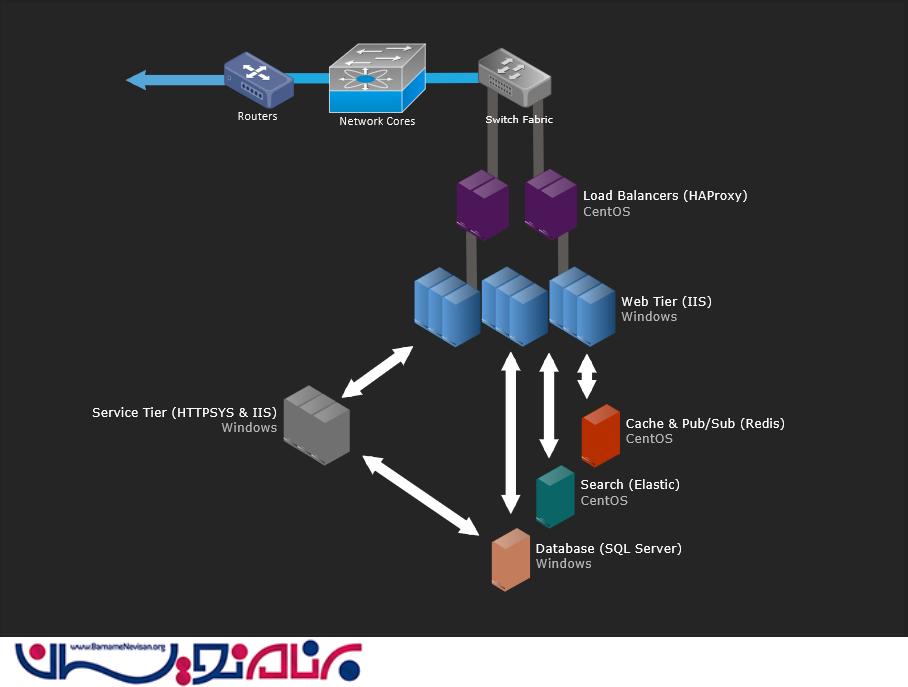
قوانین اساسی
قوانینی که در اینجا مطرح می شوند، یک سری قوانین کلی هستند که به صورت گسترده و در همه سطوح مورد استفاده قرار می گیرند. بنابراین آن ها را هر بار و در هر مرحله تکرار نمی کنیم.
همه موارد و تجهیزات به میزان بیش از حد نیاز نیز موجود هستند. (یعنی در صورت نیاز، می توانیم از تجهیزات اضافی استفاده کنیم.)
همه سرور ها و تجهیزات شبکه حداقل دو اتصال 2x 10Gbps دارند.
همه سرور ها دو منبع تغذیه دارند، همچنین دو منبع نیز وجود دارند که به وسیله دو واحد UPS که به دو منبع تغذیه بزرگتر و قوی تر متصل هستند، پشتیبانی می شوند.
همه سرور ها یک رابط مجزا بین rack A و Bدارند.
همه سرور ها و سرویس ها به یک data center مجزا متصل هستند(در Colorado) ، که البته در این جا ما بیشتر بر روی مرکز واقع در نیویورک صحبت می کنیم.
اینترنت ها
در ابتدا شما نیا دارید تا DNS ما را پیدا کنید. دسترسی و پیدا کردن سایت ما باید برای کاربران سریع باشد، بنابراین ما این کار را بر عهده ی CloudFlare گذاشتیم، زیرا آن ها تقریبا در همه نقاط دنیا، DNS server هایی در اختیار دارند. ما به روز رسانی رکوردهای موجود بر روی DNS را با استفاده از یک API انجام می دهیم و CloudFlare ، وظیفه میزبانی DNS را انجام می دهد. اما از آنجایی که ما با مسائل امنیتی مهمی سر و کار داریم، سرورهای DNS مخصوص خودمان را نیز داریم.
بعد از این که DNS ما را پیدا کردید ، HTTP traffic از یکی از چهار ISP ی ما عبور می کند (Level 3, Zayo, Cogent, و Lightower در New York) و سپس از طریق یکی از چهار روتر ما به مقصد می رسد. ما با استفاده از BGP (که نسبتا استاندارد محسوب می شود.) به ISP ها متصل می شویم تا بتوانیم روند ترافیک را کنترل کنیم و مسیرهای بهینه ای را برای عبور ترافیک ها فراهم کنیم. از هر کدام از روتر های ASR-1001 و ASR-1001-X دو عدد در اختیار داریم که هر کدام، 2 تا از ISP ها را در حالت active/active سرویس دهی می کنند، بنابراین نیازی به دخالت نیروی انسانی نیست. همه ی این تجهیزات در یک شبکه فیزیکی 10Gbps قرار دارند ، ولی ترافیک اضافی سیستم بر روی یک VLAN اضافی به صورت جداگانه قرار می گیرد که load balancer ها نیز به آن متصل هستند. زمانی که از روترها عبور کردید، به سمت یک load balancer هدایت خواهید شد.
الان، زمان خوبی برای گفتن این نکته است که ما، مابین دو data center ، به میزان 10Gbps ، MPLS داریم ، اما این مقدار مستقیما برای سایت مصرف نمی شود. ما از آن برای کپی کردن اطلاعات و بازیابی سریع آن ها در موارد ضروری بهره می گیریم که این موضوع، مزایا و معایب خودش را دارد.
Load Balancer ها (HAProxy)
load balancer ها ، HAProxy 1.5.15 را بر روی CentOS 7 اجرا می کنند، اما ترجیح ما Linux است. در این حالت، TLS (SSL) traffic نیز در HAProxy از بین می رود.
بر خلاف سایر سرور ها که یک اتصال دوگانه شبکه ای 10Gbps LACP دارند، هر load balancer دو جفت 10Gbps در اختیار دارد.: که یکی از آن ها برای شبکه خارجی و دیگری برای DMZ مورد استفاده قرار می گیرد. این موارد، 64GB و یا میزان بیشتری از حافظه را اشغال می کنند تا بتوانند به صورت بهینه تری، به مدیریت روابط مربوط به SSL ها بپردازند. زمانی که می توانیم TLS session های بیشتری را برای استفاده مجدد در حافظه نگه داریم، نیاز ما به ارتباطات جایگزین برای محاسبات مورد نیاز برای همان کاربر کمتر خواهد بود. این گفته ، به این معنی است که session ها که سریع تر و ارزان تر هستند ،می توانند چندین بار مورد استفاده قرار بگیرند.
load balancer ها خودشان تنظیمات ساده ای دارند. ما به بررسی درخواست های سایت هایی که بر روی IP های مختلفی قرار دارند، می پردازیم (اغلب برای مدیریت DNS و مسائل امنیتی ) و سپس آن ها را به backend هایی متناسب با host header هدایت می کنیم. تنها چیزی که در اینجا حائز اهمیت است ، محدودیت رتبه بندی و برخی header capture ها (که از لایه web ارسال می شوند) در HAProxy syslog message است که ما به وسیله همین ویژگی می توانیم میزان بازدهی و راندمان را به ازای هر درخواست به دست بیاوریم.
(IIS 8.5, ASP.Net MVC 5.2.3, and .Net 4.6.1) لایه وب
load balancer ها ترافیک مورد نیاز برای 9 سرور که ما آن ها را "اصلی-primary" می نامیم و همچنین 2 وب سرور “dev/meta” را تامین می کنند. سرور های primary مواردی مانند Stack Overflow, Careers و همه سایت های پرسش و پاسخ مشابه بجز meta.stackoverflow.com و meta.stackexchange.com (زیرا این سایت ها برای اجرا شدن ، حداقل به 2 سرور نیاز دارند. )را بر روی خودشان اجرا می کنند. برنامه Q&A هم خودش یک multi-tenant محسوب می شود، به این معنا که این برنامه درخواست های مربوط به همه ی سایت های Q&A (پرسش و پاسخ) را مدیریت و سرویس دهی می کند. به عبارت دیگر،ما می توانیم تمامی شبکه های مربوط به Q&A را که بر روی یک application pool واحد و یک سرور قرار دارند را به صورت یکجا اجرا کنیم. برنامه های دیگر مانند Careers, API v2, Mobile API و غیره به صورت جداگانه فعالیت می کنند. در تصویر زیر می توانید لایه های primary و dev را مشاهده کنید:
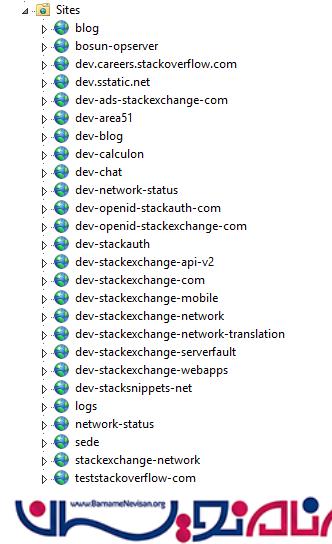
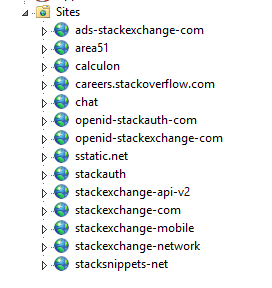
در تصویر زیر گستردگی Stack Overflow بر روی web tier (لایه وب ) در Opserver را می توانید مشاهده کنید:
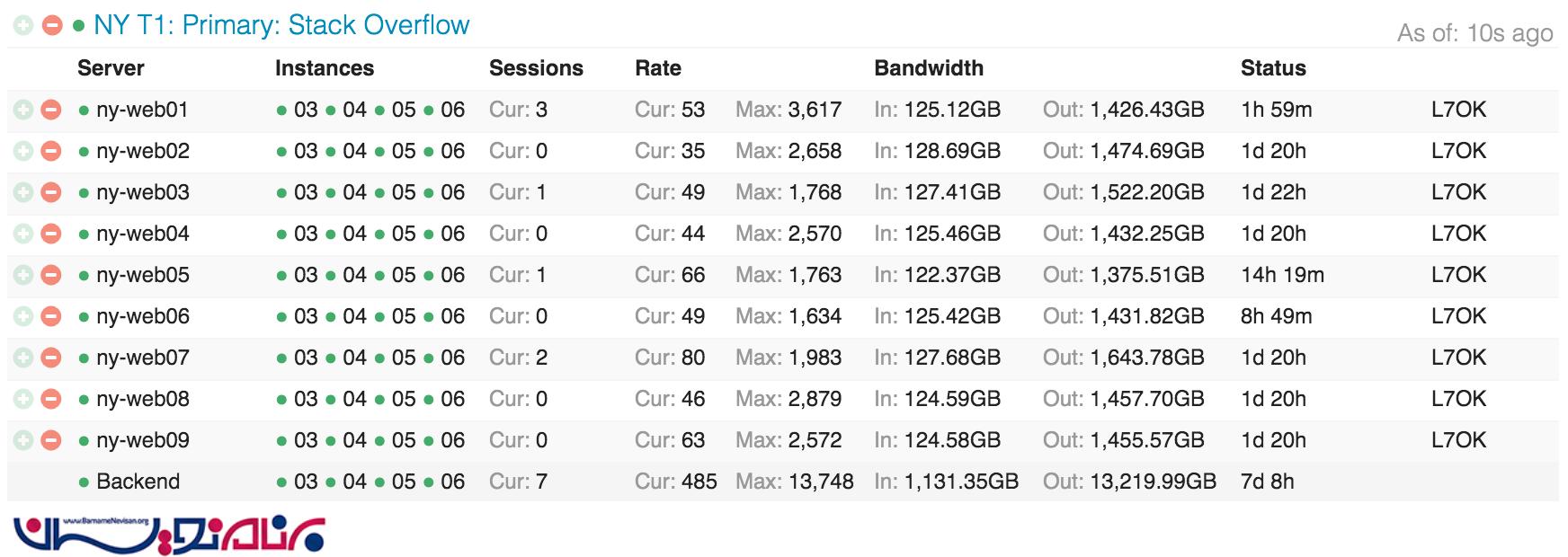
و در زیر می توانید مرتب سازی وب سرور ها از نظر بهینه سازی را مشاهده کنید:

لایه سرویس (IIS, ASP.Net MVC 5.2.3, .Net 4.6.1, و HTTP.SYS)
پشت پرده همه این وب سرویس ها مشابه است و لایه ای به نام service (service tier.) وجود دارد. که در حال حاضر IIS 8.5 را بر روی Windows 2012R2 نیز اجرا می کند. این لایه، سرویس های داخلی را برای پشتیبانی از تولید لایه وب و سایر سیستم های داخلی اجرا می کند. دو عاملی که در اینجا نقش مهم و حیاتی دارند عبارتند از : “Stack Server” که tag engine را اجرا می کند و مبتنی بر http.sys است و دیگری Providence API است که مبتنی بر IIS است.
این بسته های سرویس ، کارهای سنگین را با tag engine و API های پشتیبان انجام می دهند، و این دقیقا زمانی است که افزونگی نیاز داریم ولی این افزونگی نباید از نوع افزونگی 9x باشد. به عنوان مثال، بارگذاری همه پست ها و تگ های مربوط به آن ها که هر یک ثانیه یک بار باید از پایگاه داده خوانده شوند، کار چندان سبکی نیست. ما نمی خواهیم این بارگذاری 9 بار بر روی لایه وب انجام بگیرد. سه بار برای این کار، کافی است و همچنین امنیت را نیز برای ما تامین می کند. ما همچنین پیکربندی متفاوتی برای این بسته های سرویس در بخش سخت افزاری در نظر می گیریم تا بتوانند وظایف محاسباتی و سایر وظایف محوله را به بهینه ترین صورت انجام بدهند.اگر بخواهیم به صورت خیلی خلاصه شما را با “tag engine” آشنا کنیم می توانیم اینطور بگوییم که زمانی که شما /questions/tagged/java را بازدید می کنید، در حقیقت tag engine را به کار می اندازید تا سوال های مشابه این مورد را برای شما پیدا کرده و بیاورد. این کار همچنین در بخش /search نیز به همین صورت انجام می شود.
Cache & Pub/Sub (Redis)
ما از Redis در سایت مان به میزان کمی استفاده می کنیم. به رغم وجود حدودا 160 بیلیون عملیات در یک ماه، میزان استفاده از CPU کمتر از 2% است. در برخی موارد، حتی از این مقدار نیز کمتر می باشد:
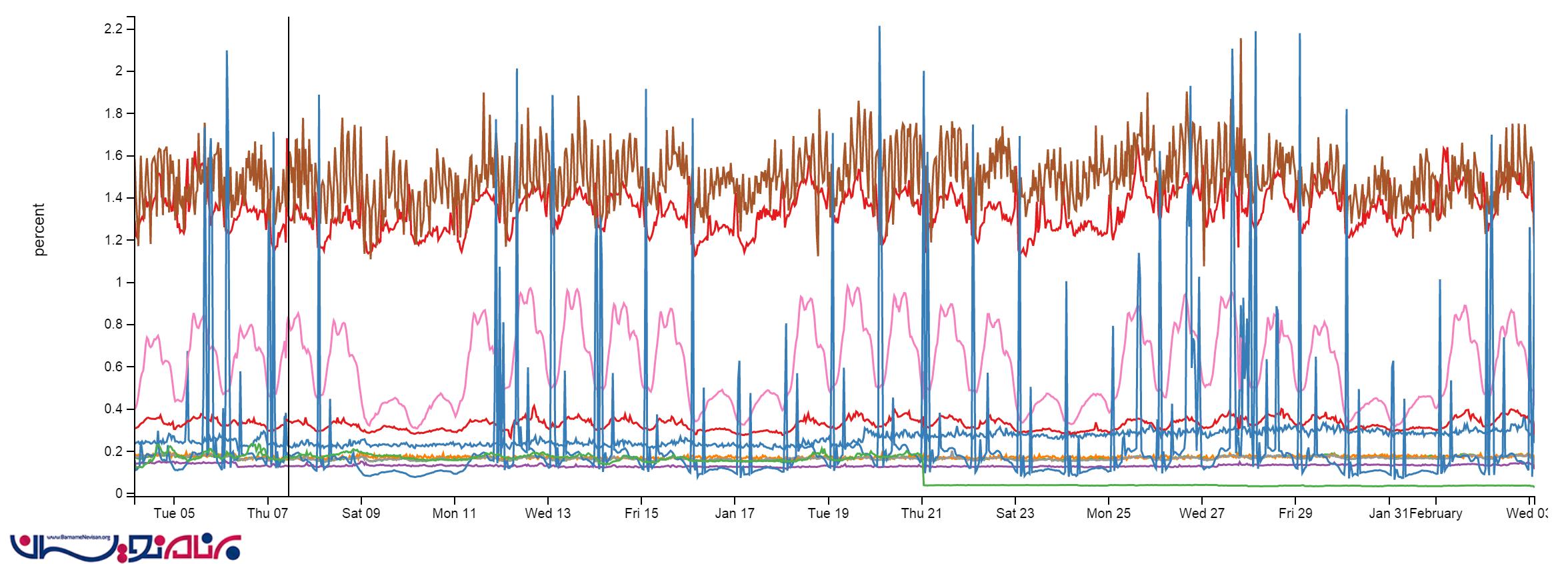
ما در Redis ، یک سیستم L1/L2 cache در اختیار داریم. “L1” مربوط به HTTP Cache بر روی وب سرور ها است. “L2” پس از انجام عملیات، به Redis باز می گردد و مقدار مورد نظر را واکشی و یا استخراج می کند. مقادیر ما با استفاده از protobuf-dot-net در Protobuf format ذخیره می شوند. برای یک کاربر ، ما از StackExchange.Redis استفاده می کنیم که open source نیز هست. زمانی که یک وب سرور ، مقداری را دریافت می کند که در L1 و L2 وجود ندارد، آن مقدار را از منبع می گیرد.(با استفاده از یک کوئری به SQL ، فراخوانی API و غیره) و سپس مقدار گرفته شده را هم در cache محلی و هم در Redis قرار می دهد. در درخواست بعدی سرور ، ممکن است مقدار در L1 موجود نباشد، ولی به صورت قطعی در L2/Redis وجود خواهد داشت.
ما همچنین سایت های پرسش و پاسخ زیادی را اجرا می کنیم که هر سایت، L1/L2 caching مخصوص به خودش را دارد. که این caching ها در L1 با پیشوند کلیدی (key prefix) و در L2/Redis با ID مربوط به پایگاه داده انجام می شود.
در کنار 2 سرور اصلی Redis (master/slave) که همه نمونه های سایت را اجرا می کنند، ما همچنین یک نمونه ماشینی یادگیرنده داریم که بین دو سرور مجزا قرار می گیرد . این ماشین برای تشخیص سوالات مشابه در صفحه اصلی به کار می رود و با هدف مورد نظر ما نیز انطباق بیشتری دارد.
سرور های اصلی Redis ، 256GB رم دارند(که 90GB آن استفاده شده است) و سرور های Providence ، 384GB رم دارند. (که 125GB آن استفاده شده است.)
Redis علاوه بر cache ، مکانیسم publish و subscriber نیز دارد که با استفاده از آن، یک سرور می تواند یک پیام را publish کند و سپس تمامی مشترکان آن سرور، می توانند آن پیام را ببینند. –کاربران سطوح پایینی در زیرمجموعه های Redis نیز می توانند پیام را دریافت کنند. ما از این مکانیسم برای پاک کردن cache های L1 که بر روی سرور های دیگر قرار دارند(که اغلب زمانی استفاده می شود که بر روی وب سرور ، برای ایجاد یکپارچگی، عمل حذف انجام می شود) استفاده می شود اما علاوه بر این مورد، یک استفاده مفید دیگر نیز دارد که websocket ها هستند.
Websockets (NetGain)
ما از websocket ها برای به روز رسانی های real-time برای کاربران مانند اطلاعیه های مورد نیاز کاربر (که در نوار بالای صفحه نمایش داده می شوند)، تعداد رای های مربوط به نظرسنجی ها، سوالات و کامنت های جدید و موارد دیگر استفاده می کنیم.
سرور های socket خودشان از socket های خاصی استفاده می کنند که در لایه وب قرار دارند. این مورد، یک برنامه بسیار سبک است که در کتابخانه open source ما قرار دارد: StackExchange.NetGain . در بهترین حالت، ما حدود 500,000 اتصال باز websocket همزمان داریم. این میزان، شامل تعداد زیادی از مرور گرها می شود.برخی از این مرورگر ها بیش از 18 ماه نیز باز باقی مانده اند. ما از دلیل این اتفاق مطمئن نیستیم. در زیر الگویی از websocket های همزمان این هفته را مشاهده می کنید.
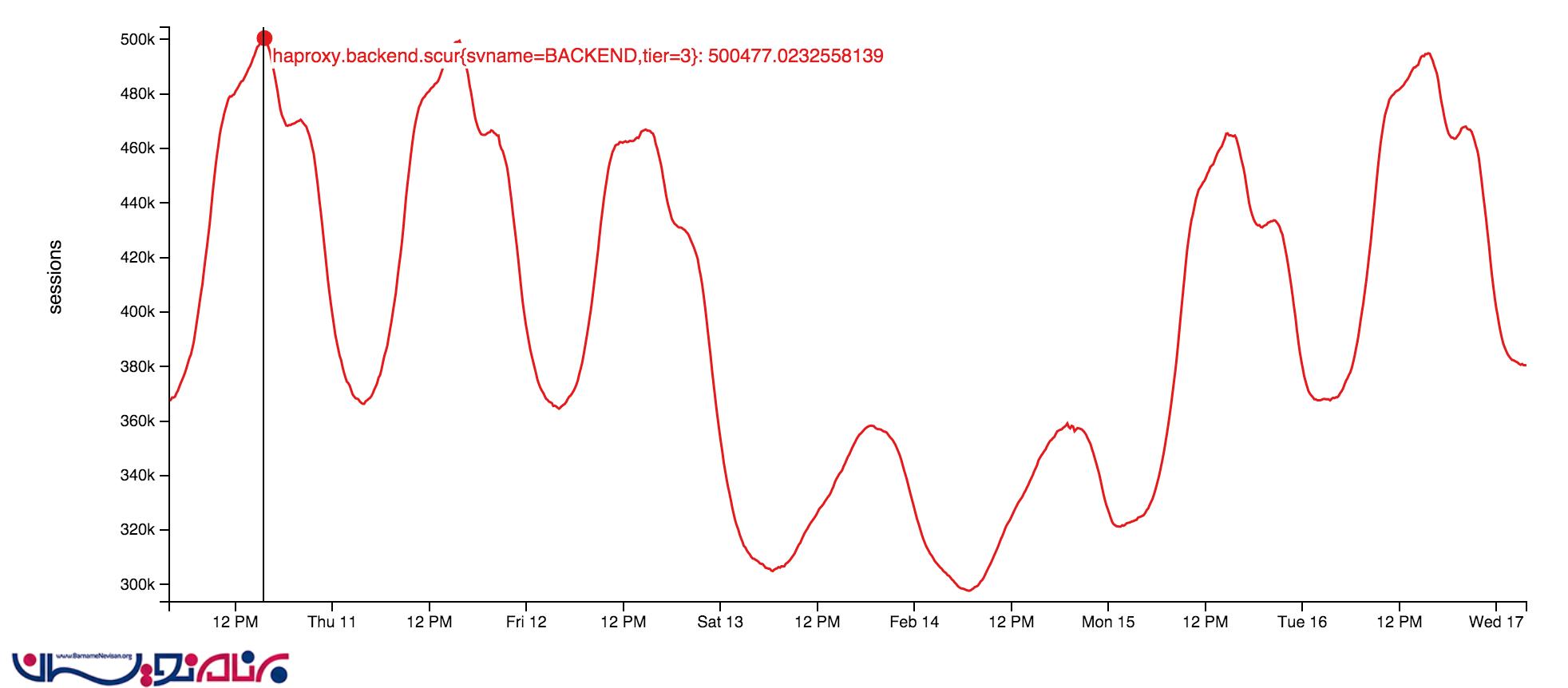
چرا باید از websocket ها استفاده کنیم؟ نکته این جاست که آن ها در حقیقت راندمان کار ما را تا میزان بسیار زیادی بالا می برند. ما با استفاده از آن ها می توانیم داده های بیشتری را با صرف منابع کمتر ، وارد سیستم کنیم ، که در این صورت دسترسی به آن ، برای کاربر نیز سریع تر خواهد بود. البته استفاده از آن ها می تواند مشکلاتی نیز به همراه داشته باشد که در مقاله های بعدی راجع به آن ها صحبت خواهیم کرد.
جستجو (Elasticsearch)
نکته زیادی در این مبحث وجود ندارد که از شنیدن آن متعجب و شگفت زده شویم. لایه وب در حال حاضر جستحوها را به راحتی از طریق Elasticsearch 1.4 و با استفاده از StackExchange.Elastic (که بسیار سبک است ولی کارایی بسیار بالایی دارد ) انجام می دهد . بر خلاف اغلب موارد،ما هیچ فکر و تصمیمی برای open source کردن این ویژگی نداریم زیرا این مورد فقط یک جایگزین سبک برای API ای که ما از آن استفاده می کنیم، محسوب می شود. ما از elastic برای /search استفاده می کنیم که سوالات مشابه را تشخیص می دهد، و در زمان پرسیدن سوال، موارد مشابه را برای کاربر نمایش می دهد.
هر شاخه و به عبارتی هر بخش از Elastic (در هر مرکز، یک بخش از Elastic وجود دارد ) سه گره دارد، و هر سایت نیز index خودش را دارد. Career ها نیز هر کدام index های اضافی خودشان را دارند. تنها موردی که تنظیمات ما را کمی از حالت استاندارد در دنیای elastic خارج می کند، این است که سه تا از سرور ها نسبت به سرور های عادی سنگین تر هستند ، زیرا حافظه SSD ، 192GB RAM و دو شبکه 10Gbps دارند.
دامنه های یکسان برنامه ها (در این جا از .Net Core نیز استفاده کرده ایم ) در سرور Stack که میزبانی tag engine را انجام می دهد ، به صورت پیوسته به index کردن آیتم ها در Elasticsearch نیز می پردازد. ما در اینجا از یک حقه ساده مانند ROWVERSION در SQL Server استفاده می کنیم . در این روش اگرچه ترتیب آیتم ها برایش مهم است ولی ما به سادگی می توانیم هر آیتمی را که اخیرا تغییر کرده است را index گذاری مجدد کنیم.
دلیل اصلی ای که ما از Elasticsearch به جای مواردی مانند SQL full-text search استفاده می کنیم ، مقیاس پذیری بالاتر و همچنین درآمدزایی بیشتر آن است . SQL CPU ها در مقایسه با Elasticsearch ها بسیار گران تر هستند، در حالی که Elastic ارزان تر است و امکانات بیشتری نیز دارد. چرا از Solr استفاده نمی کنیم؟ ما می خواهیم جستجوهایمان را در کل شبکه انجام بدهیم و این مورد در Solr پشتیبانی نمی شود. دلیل این که ما هنوز بر روی 2.x نرفته ایم، نیز این است که برای این کار نیاز داریم تا همه موارد را برای به روز رسانی دوباره index کنیم و ما هنوز زمان کافی برای این کار و مهاجرت به نسخه های بالاتر را پیدا نکرده ایم.
پایگاه داده (SQL Server)
ما از SQL Server به عنوان single source of truth خودمان استفاده کرده ایم. همه داده ها در Elastic و Redis از SQL Server گرفته می شوند. ما دو سرور SQL همراه با AlwaysOn Availability Groups اجرا می کنیم. هر کدام از این بخش ها ، یک master دارد (که همه بارگذاری های لازم را برعهده دارد.) و یک replica در نیویورک دارد. علاوه بر این موارد، یک replica در Colorado نیز وجود دارد. ( در DR data center ). همه ی replica ها به صورت ناهمزمان فعالیت می کنند.
اولین بخش (یا شاخه ) مجموعه ای از سرور های Dell R720xd است که هر کدام 384GB RAM، 4TB فضای PCIe SSD ، و 2x 12 هسته دارند. این بخش، میزبانی Stack Overflow ، PRIZM و پایگاه داده های موبایل را بر عهده دارد.
بخش دوم، مجموعه ای از سرورهای Dell R730xd است، که هر کدام 768GB RAM، 6TB فضای PCIe SSD و 2x 8 هسته دارند. این بخش، سایر موارد را اجرا می کند. که شامل Careers, Open ID, Chat, Exception log و سایت های پرسش و پاسخ دیگر است . (به عنوان مثال Super User, Server Fault)
بهینه سازی بر روی لایه پایگاه داده ، موردی است که ما می خواهیم آن را در پایین ترین سطح نگه داریم، ولی در حال حاضر به چند دلیل ، میزان آن کمی بالا رفته است. در حال حاضر ، NY-SQL02 و 04 ، master های ما هستند ، 01 و 03 ، replica هایی هستند که ما پس از یک به روز رسانی SSD، آن ها را به کار گرفته ایم. تصویر زیر 24 ساعت گذشته را نمایش می دهد.

استفاده از SQL بسیار ساده است ، که این سادگی باعث بالا بودن سرعت آن می شود . اگرچه بعضی از Query ها میتواند به قدر دیوانه کننده ای سخت باشند ، اما تعامل ما با SQl منصفانه است . ما یکسری قسمت های مربوط به LINQ to SQl داریم ، اما تقریبا همه پیاده سازی ها و توسعه های جدید از Dapper استفاده میکنند . به عبارت دیگر : stack overflow یک store procedure در پایگاه داده خود دارد و ما درنظر داریم این موارد باقی مانده از قبل را به بخش code منتقل کنیم .

- برنامه نویسان
- 4k بازدید
- 3 تشکر