اصل وابستگی معکوس (DIP) با #C
شنبه 18 دی 1395هدف از ارائه این مقاله آشنایی با DIP - Dependency Inversion Principle یا اصل وابستگی معکوس می باشد . اصل وابستگی معکوس به ما نمی گوید که چگونه وابستگی ها را از بین ببریم ، این فقط ما را در زمان طراحی راهنمایی میکند و این امکان را به ما میدهد که راحت تر برنامه را در iSolution تست کنیم .
 با #C")
حالت های اصل وابستگی معکوس بر طبق ویکی پدیا بصورت زیر می باشد :
• ماژول های High-level بهتر که با ماژول های low-level وابستگی نداشته باشند ، و بهتر است که هر دوی آنها به Abstractionها وابستگی داشته باشند .
• Abstractionها بهتر است که به جزئیات وابستگی نداشته باشند ، و بهتر است که جزئیات به abstractionها وابسته باشند .
در معماری های قدیمی و سنتی ماژول های "Higher" به ماژول های "lower" وابسته بودند . ما در برنامه با یک لایه Presentation ، یک لایه Application ، یک لایه business و یک لایه data کار میکنیم . لایه Presntation بالا ترین لایه برنامه است که در معماری های قدیمی بصورت مستقیم به لایه Application وابستگی داشت ، یا بصورت مستقیم با آن در ارتباط بود . لایه Application در بالای لایه business قرار دارد و در معماری های قدیمی بصورت مستقیم به لایه Business وابستگی داشت ، یا بصورت مستقیم با آن در ارتباط بود .
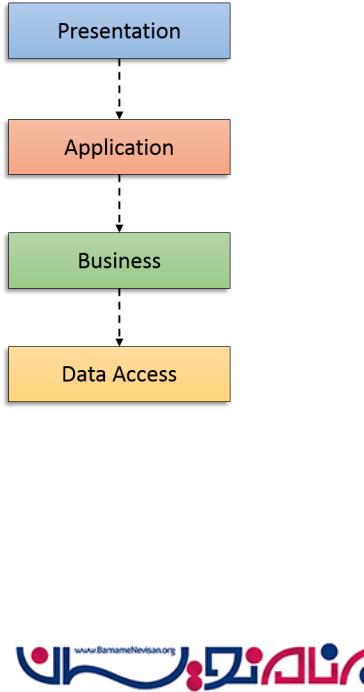
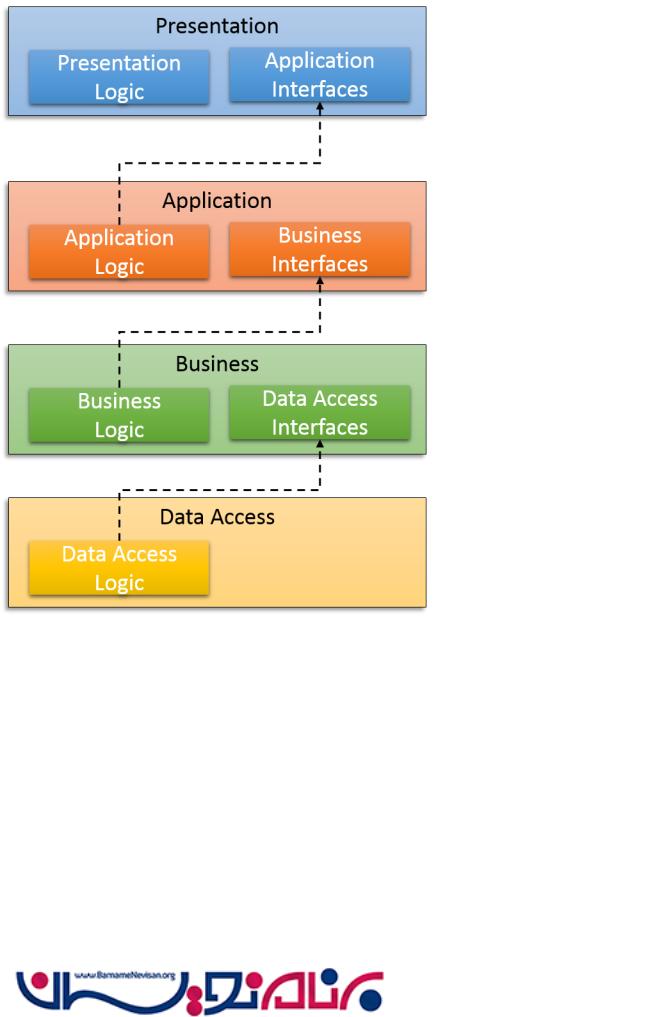
هنگامی که اصل وابستگی وارون استفاده شده است این رابطه معکوس شده است . لایه Presentation abstractionهایی که برای تعامل با یک لایه Application نیاز دارد ، را تعریف می کند . لایه Application abstractionهایی که برای تعامل با یک لایه Business نیاز دارد ، را تعریف می کند و همچنین لایه Business abstractionهایی که برای تعامل با یک لایه ی Data نیاز دارد ، را تعریف می کند . این یک حرکت کلیدی در رویکرد های کلاسیک میباشد که لایه های بالاتر Abstractionهایی که برای انجام کار خود به آن نیاز دارد را تعریف میکند و لایه های پایین تر آن Abstraction ها را پیاده سازی میکنند .
یک برنامه دقیق از DIP حتی ممکن تعریف Abstraction ها را درآن لایه قرار دهد ، برای مثال ، لایه Presentation شامل Persentation logic و abstractionهای لایه Application میباشد و Application assembly شامل application logic و abstractionهای لایه Business می باشد و ... . در این برنامه ، لایه data access به لایه business وابسته است ، business به لایه Application وابسته است ، application به لایه presentation وابسته است . این وابستگی است که در نهایت نسبت به اصل معکوس شده است .
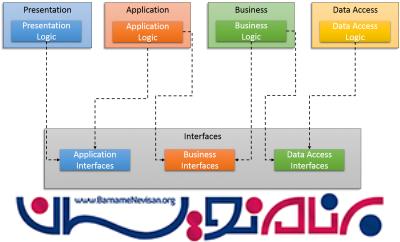
ساختار بالا برای ما یک مقدار عجیب به نظر می رسید به همین ما در تمام پروژه های خود با هر پیچیدگی ای از ساختاری شبیه تصویر زیر استفاده می کنیم . Presentation , Application , Business , Data Access همگی در assemblyهای جداگانه قرار گرفته اند . Intrerfaceها نیز در Assembly یا Assemblyهای جداگانه قرار خواهند گرفت .
دومین قسمت از وضعیت های اصل ما این بود که Abstractionها به جزئیات وابستگی نداشته باشند و این جزئیات باشند که به Abstractionها وابستگی داشته باشند ، این پتانسیل بروز مشکل در ++C را حل میکند بدین صورت بود که header میتوانست شامل توابع و متغیرهای Public و Private باشند ، خب در ++C این به معنای استفاده از یک کلاس Pure Abstraction می باشد . در #C کلاس Pure Abstract همان Interface است یا یک کلاس Abstract بدون هیچ پیاده سازی .
ما با استفاده از Mocks, Fakes, test doubles و ... میتوانیم هر الیه از برنامه خود را تست کنیم . در اینجا یک مثال فوق العاده مطرح می شود . شرکت ما دارای بیزینس تولید Widget میباشد . در قسمتی از طراحی برنامه ما دریافتیم که ما نیاز به log کردن اطلاعات داریم و اولین نیازمان برای این کار تعامل با لیست تراکنش های Widgetها بود . به همین دلیل ما یک Interface assembly بصورت زیر ایجاد کردیم و آن را به interface اضافه کردیم :
NAMESPACE DIP.INTERFACES
{
PUBLIC INTERFACE IWIDGET
{
INT LENGTH { GET; SET; }
INT WIDTH { GET; SET; }
BOOL DOWORK();
}
}
NAMESPACE DIP.INTERFACES
{
PUBLIC INTERFACE ILOGGER
{
//LOGGINGCONCERNS
BOOL LOGMESSAGE(STRING MESSAGE);
BOOL LOGMESSAGE(STRING MESSAGE, STRING CALLSTACK);
}
}
USING SYSTEM.COLLECTIONS.GENERIC;
NAMESPACE DIP.INTERFACES
{
PUBLIC INTERFACE ICOORDINATINGSERVICE
{
VOID COORDINATETRANSACTION(ILIST<IWIDGET> WIDGETS);
}
}
برای لایه Data access ما Loggingهای مختصری را در نظر میگیریم . ما دریافتیم ، ما نیاز داریم که امکان log به پایگاه داده یا یک فایل را داشته باشیم به همین دلیل یک پروژه جدید اضافه میکنیم که دو کلاس همانند زیر ایجاد میکند :
USING DIP.INTERFACES;
NAMESPACE DIP.STORAGE
{
PUBLIC CLASS FILELOGGER:ILOGGER
{
PUBLIC BOOL LOGMESSAGE(STRING MESSAGE)
{
//WRITE TO FILE
RETURN TRUE;
}
PUBLIC BOOL LOGMESSAGE(STRING MESSAGE, STRING CALLSTACK)
{
//WRITE TO FILE
RETURN TRUE;
}
}
}
USING DIP.INTERFACES;
NAMESPACE DIP.STORAGE
{
PUBLIC CLASS DBLOGGER:ILOGGER
{
PUBLIC BOOL LOGMESSAGE(STRING MESSAGE)
{
//WRITE TO DATABASE
RETURN TRUE;
}
PUBLIC BOOL LOGMESSAGE(STRING MESSAGE, STRING CALLSTACK)
{
//WRITE TO DATABASE
RETURN TRUE;
}
}
}
خوشبختانه ، Data Access فقط به Interface assembly وابسته می باشد .
حال ما یک لایه business اضافه میکنیم - این معمولا مهم ترین لایه است که اکثرا مقادیر توسط این لایه فراهم آورده می شود . مواظب بیشتر منطق ها میباشد و اکثرا حفره های اطلاعاتی را رفع میکند . دوباره با اضافه کردن یک پروژه جدید شروع میکنیم سپس یک کلاس Widget اضافه میکنیم :
USING DIP.INTERFACES;
NAMESPACE DIP.BUSINESS
{
PUBLIC CLASS WIDGET:IWIDGET
{
ILOGGER LOG;
//XTOR INJECTION
PUBLIC WIDGET(ILOGGER LOGGER)
{
LOG = LOGGER;
}
PUBLIC BOOL DOWORK()
{
//EXECUTE BUSINESS RULES AND LOG AN ENTRY
LOG.LOGMESSAGE("HELLO WORLD");
RETURN TRUE;
}
PUBLIC INT LENGTH { GET; SET; }
PUBLIC INT WIDTH { GET; SET; }
PUBLIC STRING OTHERSTUFFNOTPERSISTED { GET; SET; }
}
}
توجه داشته باشید که برای ایجاد Widget مانیاز به تامین یک ILogger داریم -- این Constructor Injection نامیده میشود . اگر تمامی کلاس ها به logger نیاز ندارند ما میتوانیم پارامتر ILogger را به متدی که نیاز به logger دارد اضافه میکنیم -- این method injection است . همچنین توجه داشته باشید که ، businnes بصورت مستقیم به لایه data access ازجاع ندارد - این فقط به interface assembly ارجاع هایی دارد . در زمان تست لایه business به جای استفاده از یک پایگاه داده یا یک فایل سیستم ما میتوانیم از پیاده سازی Mock برای ILogger استفاه کنیم . این در واقع شعار اصلی ، اصل وابستگی معکوس می باشد .
چیزی را که به لایه Apllication اضافه کردیم را ادامه میدهیم ، این لایه به متعادل کردن تراکنش های بین Businnes Objectهای موجود می پردازد :
USING DIP.INTERFACES;
USING SYSTEM.COLLECTIONS.GENERIC;
NAMESPACE DIP.APPLICATIONSERVICE
{
PUBLIC CLASS COORDINATINGSERVICE : ICOORDINATINGSERVICE
{
ILOGGER LOG;
PUBLIC COORDINATINGSERVICE(ILOGGER LOGGER)
{
LOG = LOGGER;
}
PUBLIC VOID COORDINATETRANSACTION(ILIST<IWIDGET> WIDGETS)
{
//BEGIN TRANSACTION
FOREACH(VAR ITEM IN WIDGETS)
{
ITEM.DOWORK();
}
//COMMIT...
}
}
}
دوباره ، ما برای گرفتن ILogger از Constructor Injection استفاده میکنیم . در حقیقت ، ما فقط تکیه بر IWidget و ILogger داریم ، پس ، این لایه می تواند با mock تست شود .
حال ما به سراغ UI می رویم - ما فقط از یک پروژه MVC 4 برای این استفاده کرده ایم . یک Controller اضافه کنید . ما اصل وابستگی معکوس را در اینجا رعایت نمی کنیم :
USING DIP.APPLICATIONSERVICE;
USING DIP.BUSINESS;
USING DIP.INTERFACES;
USING DIP.STORAGE;
USING SYSTEM.COLLECTIONS.GENERIC;
USING SYSTEM.WEB.MVC;
NAMESPACE DIP.UI.CONTROLLERS
{
PUBLIC CLASS WIDGETCONTROLLER : CONTROLLER
{
//
// GET: /WIDGET/
PUBLIC ACTIONRESULT INDEX()
{
//CALL THE SERVICE LAYER FOR THIS
VAR SERVICE = NEW COORDINATINGSERVICE(NEW DBLOGGER());
//NORMALLY THIS WOULD BE EXTRACTED FROM THE REQUEST
SERVICE.COORDINATETRANSACTION(NEW LIST<IWIDGET>{
NEW WIDGET(NEW DBLOGGER()){LENGTH=3,WIDTH=4},
NEW WIDGET(NEW DBLOGGER()){LENGTH=5,WIDTH=6}
});
VAR MODEL = "SUCCESS";
//SEND MODEL TO VIEW
RETURN VIEW(MODEL);
}
}
}
چگونه ما در کدهای بالا ، این اصل را رعایت نکردیم ؟
با چندین راه -- ما اسمبلی های Application , business و data access را بصورت مستقیم ارجاع داده ایم و از این item ها در Controller نمونه ساخته ایم .
به چه دلیل ما این کار را انجام داده ایم ؟
به این دلیل که اصل وابستگی معکوس به ما نمی گوید که چگونه وابستگی ها را از بین ببریم ، این فقط ما را در زمان طراحی راهنمایی میکند و این امکان را به ما میدهد که راحت تر برنامه را در iSolution تست کنیم . Solution بالا این امکان را برای ما فراهم خواهد آورد که لایه های application و business را در iSolution تست کنیم . اگر ما نیاز داریم که لایه data access را در iSolution تست کنیم ، ما به refactor کردن برنامه و استفاده بهتر از Interface ها نیاز پیدا خواهیم کرد یا ما مجبوریم که از MicroSoft Shim Framework برای بازگرداندن یکسری نتیجه و داده ، استفاده کنیم . با این طراحی ، ما میتوانیم خیلی با احتیاط بگوییم که ، لایه UI قابل تست شدن در iSolution نمی باشد .

- C#.net
- 2k بازدید
- 5 تشکر