الگوی تولیدکننده مصرفکننده درNET (C#).
سه شنبه 26 دی 1396در این مقاله الگوی تولیدکننده(Producer)-مصرفکننده (Consumer) در NET و دلایل استفاده از آن را توضیح میدهیم و مثالهایی از نحوه پیادهسازی آن در NET. را شرح میدهیم.
.")
در نتیجهی دستگاههایی که هسته پردازش چندگانه دارند، مسأله برنامهنویسی موازی (parallel) این روزها مهمتر میشود. امروزه یک رایانه معمولی چهار تا هشت هسته دارد، و سرورها نیز هستههای بیشتر از این دارند.
این مسأله باعث میشود تا نرمافزارهایی را بنویسید که از هستههای چندگانه برای کارایی بالا استفاده کنند.
کد زیر که برنامهای است که اسناد را پردازش میکند را در نظر بگیرید:
void ProcessDocuments()
{
string[] documentIds = GetDocumentIdsToProcess();
foreach(var id in documentIds)
{
Process(id);
}
}
string[] GetDocumentIdsToProcess() => ...
void Process(string documentId)
{
var document = ReadDocumentFromSourceStore(documentId);
var translatedDocument = TranslateDocument(document, Language.English);
SaveDocumentToDestinationStore(translatedDocument);
}
Document ReadDocumentFromSourceStore(string identifier) => ...
Document TranslateDocument(Document document, Language language) => ...
void SaveDocumentToDestinationStore(Document document) => ...
این کد شناسههای (id) اسنادی که باید پردازش شوند را دریافت میکند، هر سند را از مخزن منبع میگیرد (مثل پایگاه داده)، آن را ترجمه کرده و سپس آن را در مخزن مقصد ذخیره میکند.
در حال حاضر کدها فقط با یک thread اجرا میشوند.
در #C میتوانیم این کدها را برای استفاده از چندین هسته، به راحتی با استفاده از کلاس Parallel تغییر دهیم، مثل این:
void ProcessDocumentsInParallel()
{
string[] documentIds = GetDocumentIdsToProcess();
Parallel.ForEach(
documentIds,
id => Process(id));
}
این عمل Data Parallelism نامیده میشود، زیرا عملیاتی را روی هر آیتم داده اعمال کردهایم، و در این مورد خاص، روی هر id سند این کار را انجام دادهایم.
Parallel.ForEach فراخوانی متد Process را روی آیتمهای آرایه documentIds به صورت موازی انجام میدهد.
البته همه اینها به محیط بستگی دارد!
به عنوان مثال، تعداد هستههای موجود بیشتر، باعث میشود تعداد اسناد بیشتری به صورت موازی پردازش شوند.
شکل زیر را درنظر بگیرید:
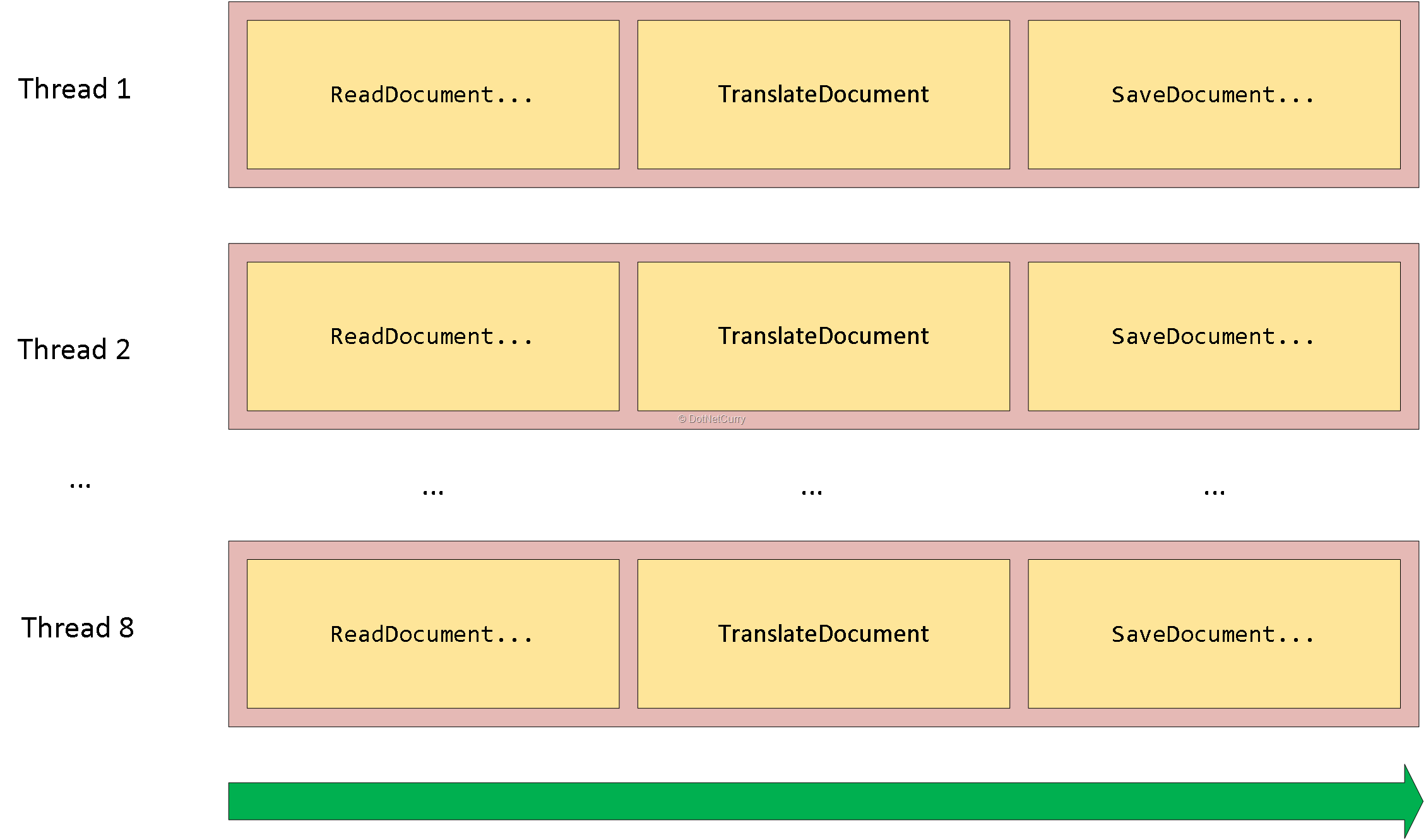
با فرض اینکه هشت thread در حال پردازش هستند، میتوانیم تصور کنیم هر یک از این threadها یک id سند را گرفته، ReadDocumentFromSourceStore ، TranslateDocument و سپس SaveDocumentToDestinationStore را فراخوانی میکند.
وقتی هر thread عملیات سند خود را انجام داد، id یک سند دیگر را میگیرد و آن را پردازش میکند. Parallel.ForEach همه این عملیات را مدیریت خواهد کرد.
اگرچه این کار ایده خوبی به نظر میرسد، ممکن است مشکلاتی با این رویکرد به وجود آیند.
ما این مشکلات را بررسی کرده و در نهایت الگوی تولیدکننده مصرفکننده را معرفی میکنیم و نشان میدهیم که این الگو چگونه برخی از این مشکلات را حل میکند.
نکته: رفتار Parallel.ForEach ( و اجزای .NET که توسط آن استفاده میشوند) پیچیده و سطح بالاست. این دستور به طور خودکار مرحله موازیسازی را مدیریت میکند. مثلا، حتی اگر دستگاه هشت هستهای باشد، سیستم اگر متوجه شود که وظایف در حال اجرا توسط I/O مسدود شدهاند، ممکن است تصمیم بگیرد بیش از هشت کار را به صورت موازی انجام دهد. برای اینکه مباحث را ساده بیان کنیم، فرض را بر این میگیریم که در دستگاهی با هشت هسته، Parallel.ForEach دقیقا هشت وظیفه را به صورت موازی اجرا میکنند.
موازیسازی ساده، ایجاد برخی مشکلات
در مثال قبل، فرض کردیم که سیستم از هشت thread (thread-pool) برای پردازش اسناد استفاده میکند. این به این معناست که سیستم میتواند در یک مثال معین، هشت thread که ReadDocumentFromSourceStore را فراخوانی میکند را داشته باشد.
اگر ReadDocumentFromSourceStore، عملیات I/O در دستگاهی باشد که موازیسازی را خوب اجرا نمیکند، این مسأله ممکن است مشکلساز شود.
به عنوان مثال، ReadDocumentFromSourceStore ممکن است اسناد را از هارد ساده بخواند. هنگام خواندن از هارد به صورت موازی، دیسک ممکن است نیاز داشته باشد تا اطلاعات را از مکانهای مختلفی بخواند. انتقال از یک مکان به مکان دیگر در هارد دیسکها آهسته است، زیرا هد فیزیکی در دیسک نیاز به جابجایی دارد.
از سوی دیگر، اگر در حال خواندن فقط یک فایل در یک زمان باشیم، احتمال دارد که محتویات فایل (یا بخش بزرگی از فایل) در یک مکان فیزیکی روی دیسک قرار گیرد و بنابراین دیسک برای جابجایی هد زمان کمتری را صرف کند.
برای رفع این مشکل، میتوانیم یک lock یا semaphore پیرامون فراخوانی متد ReadDocumentFromSourceStore قرار دهیم.
Lock اجازه میدهد فقط یک thread برای فراخوانی این عملیات در یک زمان رخ دهد، و semaphore اجازه میدهد تعداد مشخصی از threadها که از پیش تعیین شده است (مشخص شده در کد) برای فراخوانی متد در یک زمان وارد عمل شوند.
مثال زیر از یک semaphore استفاده میکند تا مطمئن شود که در هر لحظه، حداکثر دو thread متد ReadDocumentFromSourceStore را فراخوانی میکنند.
Semaphore semaphore = new Semaphore(2,2);
public void Process(string documentId)
{
semaphore.WaitOne();
Document document;
try
{
document = ReadDocumentFromSourceStore(documentId);
}
finally
{
semaphore.Release();
}
var translatedDocument = TranslateDocument(document, Language.English);
SaveDocumentToDestinationStore(translatedDocument);
}
SaveDocumentToDestinationStore نیز احتمالا با فراخوانی توسط هشت thread به صورت موازی، قادر به مدیریت نخواهند بود. در اینجا نیز میتوانیم از lock یا semaphore برای محدود کردن تعداد threadهایی که میتوانند به این متد دسترسی یابند، استفاده کنیم.
تغییر زمان اجرا
وقتی از lock یا semaphore استفاده میکنیم، برخی threadها در زمان انتظار برای اینکه نوبتشان شود تا به قسمت محفوظ شده کد مثل فراخوانی SaveDocumentToDestinationStore دسترسی یابند، مسدود خواهند شد.
مثال زیر را در نظر بگیرید:

در این مثال، هر یک از عملیات 10 میلیثانیه طول میکشد. با این حال، متد SaveDocumentToDestinationStore با یک lock محافظت میشود تا فقط یک thread بتواند آن را فراخوانی کند (به دلایل مورد بحث در بخش قبل). توجه داشته باشید که در این مثال، فرض میکنیم که ReadDocumentFromSourceStore میتواند بدون هیچ مشکلی از چند thread فراخوانی شود.
بدون lock، هر thread یک سند را در 30 میلیثانیه پردازش خواهد کرد (فرض میکنیم که تمام عملیات میتوانند بدون هیچ مشکلی به صورت موازی انجام شوند).
حالا با lock، این مسأله دیگر صحیح نیست!
یک thread 30 میلیثانیه زمان میگیرد بهعلاوه زمانی که صبر میکند تا lock را به دست آورد (نوبت آن برای اجرای SaveDocumentToDestinationStore).
به جای اینکه threadها منتظر بمانند و هیچ کاری انجام ندهند، آیا میتوانیم id اسناد دیگر را برای آنها بگیریم، اسناد را بخوانیم و آنها را ترجمه کنیم؟
شکل زیر این مورد را نشان میدهد:
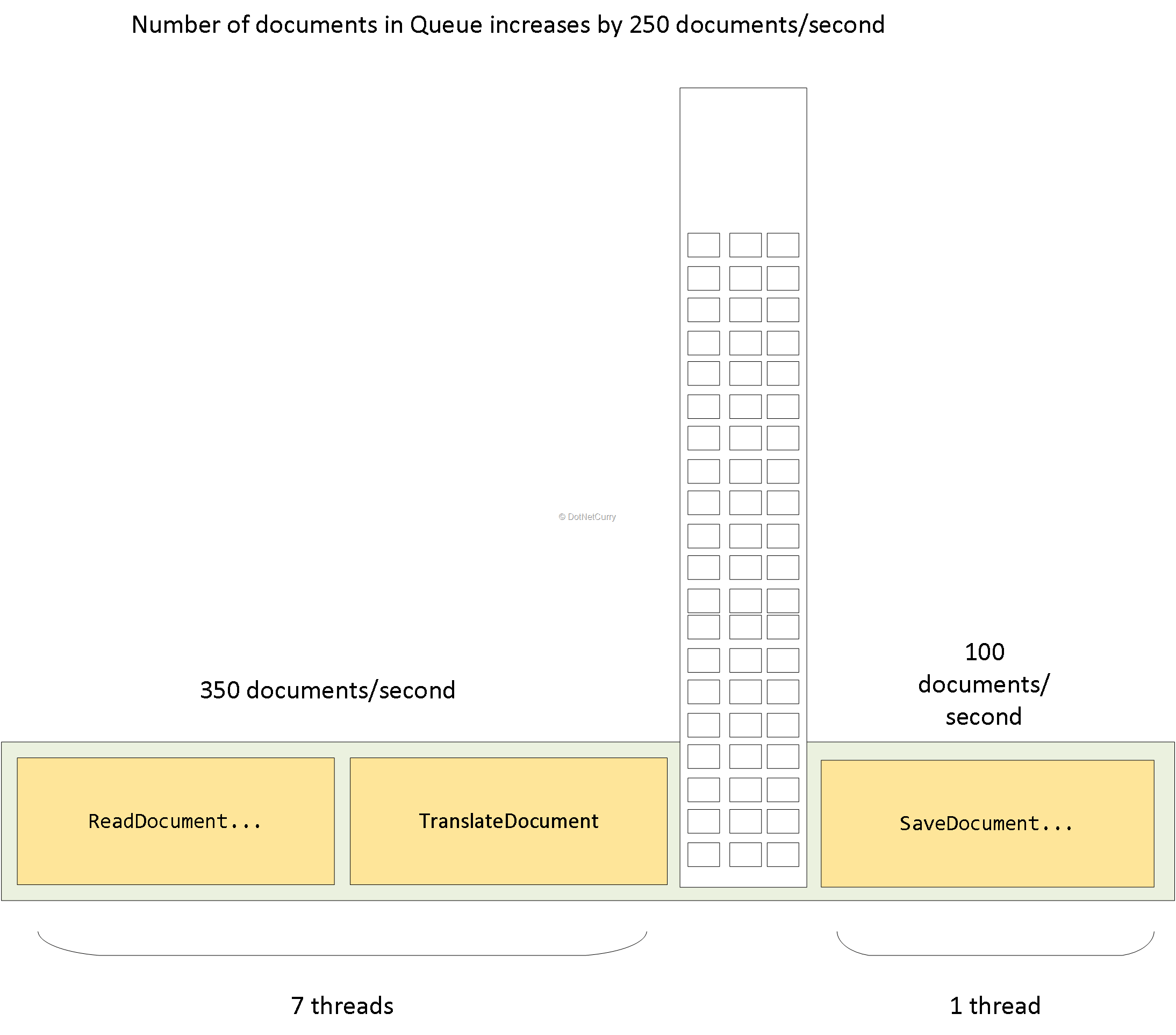
در این مثال، هفت thread اسناد را خوانده و ترجمه میکند.
هر کدام از این threadها یک شناسه سند را میگیرند، ReadDocumentFromSourceStore و TranslateDocument را فراخوانی میکنند، سپس نتیجه ترجمه را درون یک صف قرار داده و دوباره به فرآیند (خواندن و ترجمه) اسناد دیگر بازمیگردند. یک thread اختصاصی اسناد را از صف میگیرد و SaveDocumentToDestinationStore را فراخوانی میکند و سپس سند دیگری را از صف واکشی میکند و به همین ترتیب ادامه میدهد.
از آنجا که هفت thread در حال کار در سمت چپ صف قرار دارد، میتوانیم تقریبا (7 thread * (1000 ms/(10ms+10ms)=350)) سند در ثانیه را پردازش کنیم. thread موجود در سمت راست صف (1000ms/10ms=100) سند در هر ثانیه را پردازش خواهد کرد. این بدان معناست که تعداد آیتمها در صف توسط 250 سند در ثانیه افزایش خواهد یافت. بعد از اینکه همه اسناد خوانده شده و ترجمه شدند، تعداد اسناد در صف با 100 سند در ثانیه کم میشود.
بنابراین حتی اگر جزئی از (خواندن و ترجمه) اسناد را سریعتر از 100 سند در ثانیه پردازش کنیم، این اسناد پردازش شده باز هم لازم است تا در صف منتظر بمانند تا نوبت ذخیرهساز ی آنها برسد و ما هنوز هم میخواهیم به طور کلی توان عملیاتی 100 سند در ثانیه را داشته باشیم.
به طور خلاصه، با ایجاد threadها برای پردازش اسناد دیگر، به جای انتظار، هیچ چیزی به دست نمیآوریم.
نتیجهای که در بالا به آن رسیدیم درست است، زیرا ما فرض میکنیم زمانی که برای ذخیره سند صرف میکند ثابت است (مثلا 10 میلیثانیه). با این حال، در بسیاری موارد، زمان ذخیرهسازی سند اغلب تغییر میکند.
موردی را که سند در دیسکی روی دستگاهی از راه دور ذخیره میشود را در نظر بگیرید. اتصال به دستگاه از راه دور ممکن است از نظر زمانی بهتر یا بدتر شود و بنابراین زمانی که برای ذخیره سند میگیرد غالبا تغییر میکند.
برای تحلیل این مثال بیایید فرض کنیم متد SaveDocumentToDestinationStore در نیمی از زمان، 10 میلیثانیه برای تکمیل شدن صرف میکند و 2 میلیثانیه در نیمی دیگر از زمان صرف میکند (در نتیجهی بار کم شبکه).
بیایید موردی را فرض کنیم که اسناد را در طی 2 ثانیه پردازش میکنیم. در ثانیه اول، SaveDocumentToDestinationStore برای تکمیل شدن 10 میلیثانیه زمان میگیرد. در ثانیه دوم، 2 میلیثانیه زمان صرف میکند.
حالا ببینیم چه اتفاقی میافتد اگر صفی وجود نداشته باشد، یعنی وقتی threadها در انتظار رسیدن نوبتشان برای فراخوانی SaveDocumentToDestinationStore هستند، به سادگی مسدود میشوند.
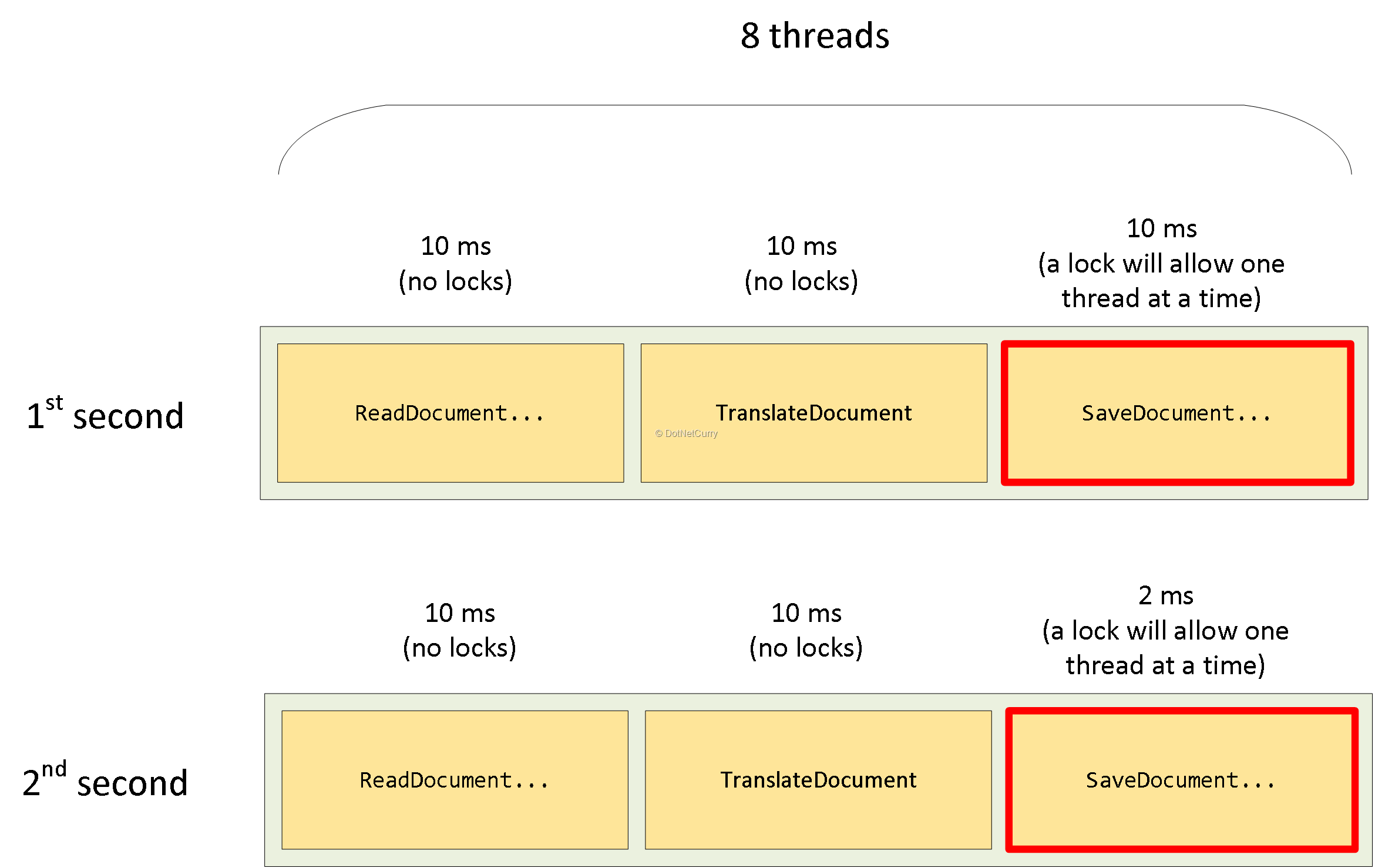
در ثانیه اول، 100 سند در ثانیه را پردازش میکنیم (به سرعت می توانیم اسناد را ذخیره کنیم) بنابراین 100 سند را پردازش میکنیم.
در ثانیه دوم، ذخیرهسازی اسناد دیگر مشکل نیست. در این ثاینه، هر سند 22 میلیثانیه + میانگین زمان انتظار برای lock را صرف می کند. ما میخواهیم این زمان انتظار را نادیده بگیریم و بگوییم (8 thread * 1000ms/22ms ~=363) سند را پردازش میکنیم (اگر زمان انتظار را درنظر گیریم این مقدار کمتر میشود).
بنابراین در فاصله دو ثانیه، تقریبا 463 سند را پردازش میکنیم.
حالا بیایید موردی را در نظر بگیریم که یک صف داریم.
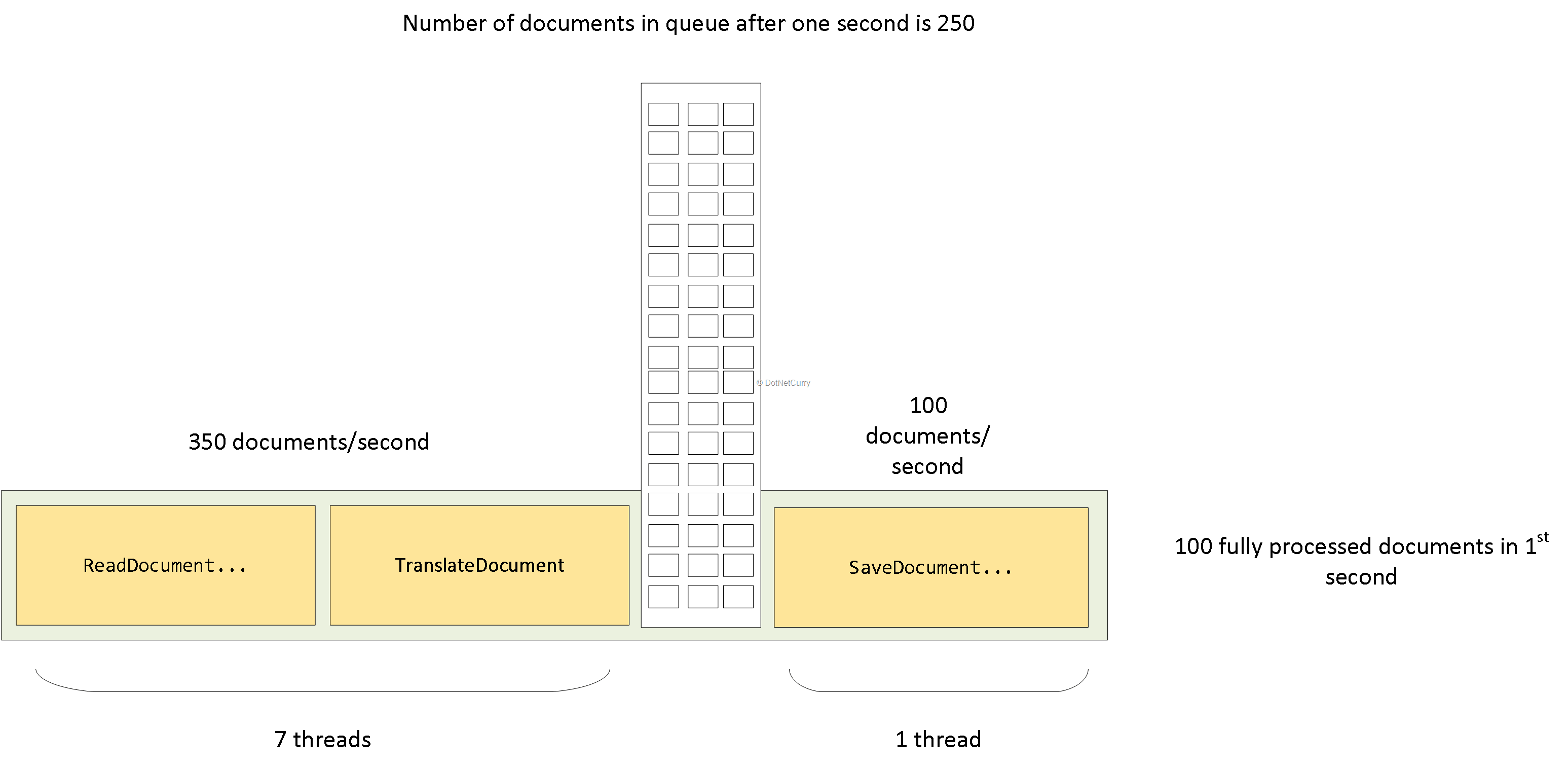
در یک ثانیه، 100 سند را کامل میکنیم. با این حال، 250 (100-310) سند اضافی داریم که خوانده و ترجمه شدهاند و در صف نشستهاند.
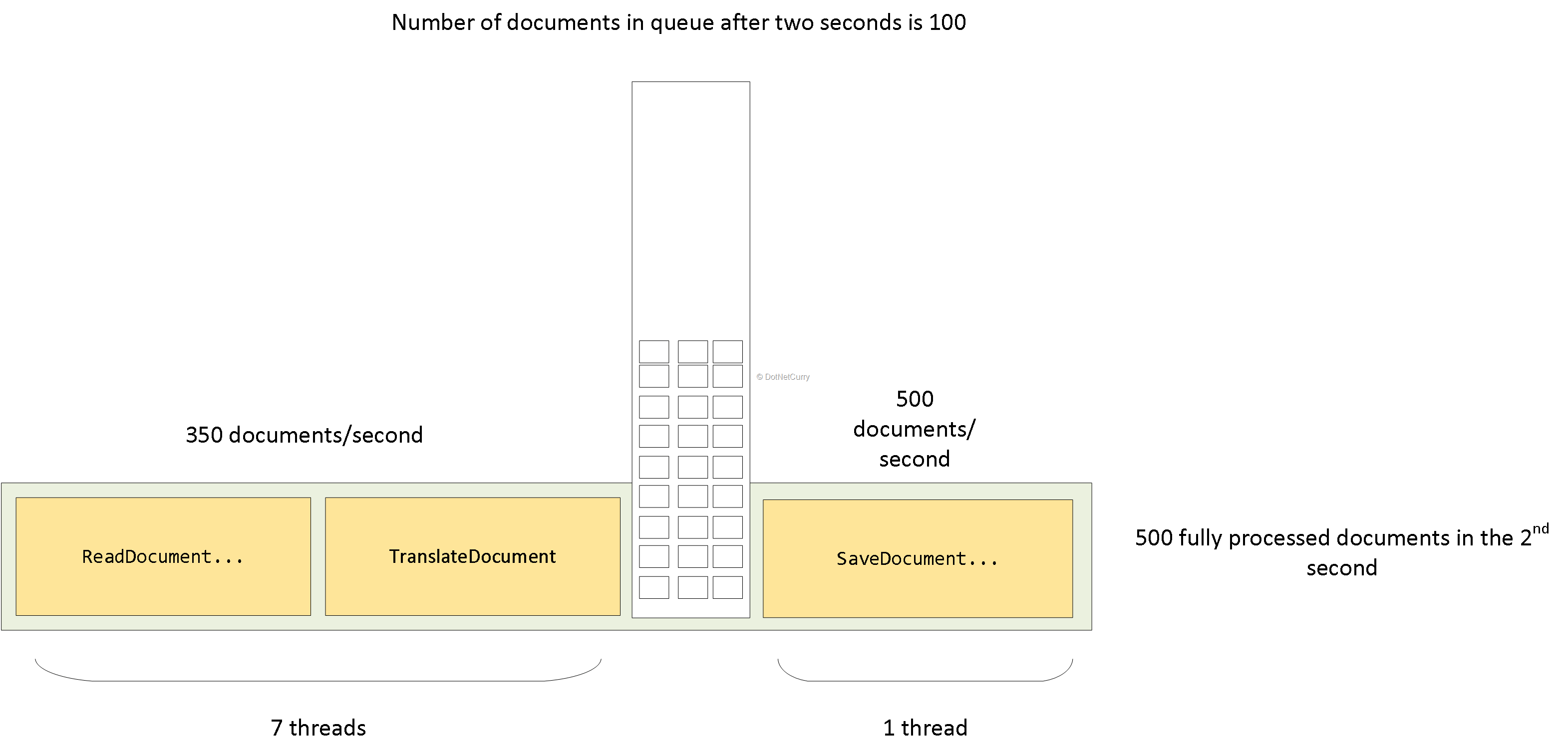
در ثانیه دوم، threadهای سمت چپ میتوانند 350 سند اضافی را در صف قرار دهند. این به این معناست که در مجموع 600 سند برای thread ذخیرهسازی جهت پردازش در دسترس هستند. Thread سمت راست 500 سند را در ثانیه دوم پردازش میکند.
این رویکرد در مجموع 600 سند پردازش شده در فاصله 2 ثانیه را به ما میدهد (1000/2).
با استفاده از این روش، حداقل بیش از 137=463-600 سند را در فاصله 2 ثانیه پردازش میکنیم.
الگوی تولیدکننده-مصرفکننده
در بخش قبل، دو روش برای پردازش اسناد به صورت موازی را ارائه دادیم.
این قبیل پردازشها سه مرحله مجزا دارد: خواندن سند، ترجمه آن و ذخیره آن.
در روش اول (بدون صف) چندین thread داشتیم که هر یک از آنها یک سند را از طریق این سه مرحله پردازش میکرد.
در روش دوم، هر مرحله (یا گروهی از مراحل) یک thread اضافی در حال اجرا داشت.
مثلا، در مثال آخر، هفت thread داشتیم که اسناد را خوانده و ترجمه میکرد، و یک thread که اسناد را ذخیره میکرد.
این اساسا الگوی تولیدکننده-مصرفکننده است.
در این مثال، ما هفت تولیدکننده داریم که اسناد ترجمهشده را تولید میکند و یک مصرفکننده داریم که این اسناد را با ذخیزه کردن آنها مصرف میکند.
در این بخش، در مورد جزئیات این الگو صحبت میکنیم و نشان میدهیم که چگونه این الگو میتواند در .NET اجرا شود.
الگوی تولیدکننده-مصرفکننده با جزئیات
وقتی الگوی تولیدکننده-مصرفکننده را به شکلی ساده اعمال میکنیم، یک thread تولیدکننده داده داریم که آنها را در یک صف قرار میدهد، و thread دیگر دادهها را از صف برداشته و آنها را پردازش میکند.
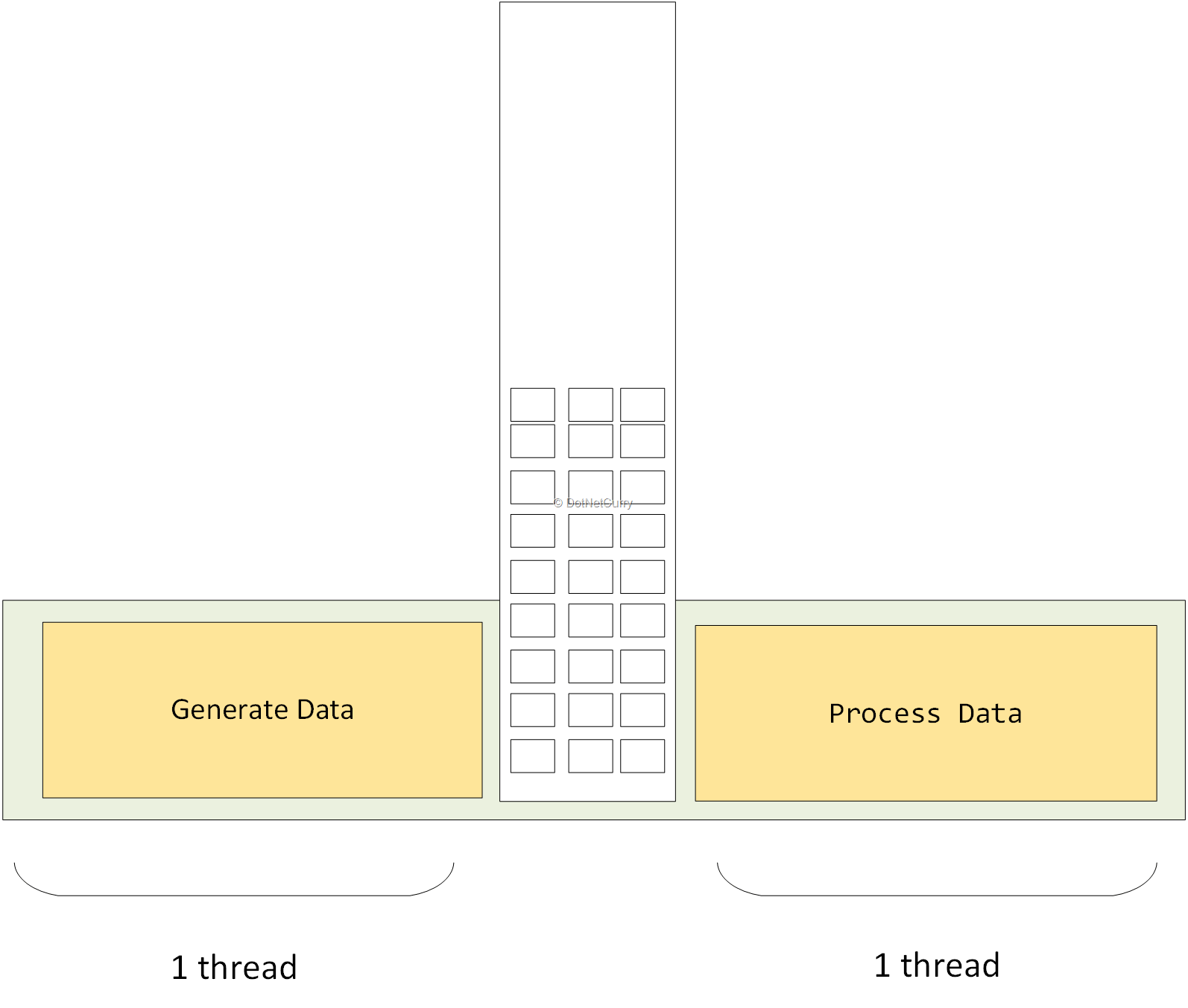
صف باید thread ایمن (thread-safe) باشد. ممکن است یک thread یک آیتم را بگذارد، در حالی که thread دیگر آیتمی را برمیدارد.
گاهی وقتها، تولیدکننده میتواند دادهها را سریعتر از پردازش مصرفکننده، تولید کند. در این مورد، باید محدوده بالایی روی تعداد دادههایی که صف می تواند ذخیره کند داشته باشیم. اگر صف پر شد، تولیدکننده باید تولید دادههای بیشتری را متوقف کند تا صف دوباره خالی شود.
پشتیبانی از الگوی تولیدکننده-مصرفکننده در NET framework.
سادهترین راه برای اجرای الگوی تولیدکننده-مصرفکننده برای .NET، استفاده از کلاس BlockingCollection است.
کد زیر نشان می دهد که چگونه میتوانیم مثال پردازش سند را با استفاده از این کلاس اجرا کنیم:
public void ProcessDocumentsUsingProducerConsumerPattern()
{
string[] documentIds = GetDocumentIdsToProcess();
BlockingCollection inputQueue = CreateInputQueue(documentIds);
BlockingCollection queue = new BlockingCollection(500);
var consumer = Task.Run(() =>
{
foreach (var translatedDocument in queue.GetConsumingEnumerable())
{
SaveDocumentToDestinationStore(translatedDocument);
}
});
var producers = Enumerable.Range(0, 7)
.Select(_ => Task.Run(() =>
{
foreach (var documentId in inputQueue.GetConsumingEnumerable())
{
var document = ReadAndTranslateDocument(documentId);
queue.Add(document);
}
}))
.ToArray();
Task.WaitAll(producers);
queue.CompleteAdding();
consumer.Wait();
}
private BlockingCollection CreateInputQueue(string[] documentIds)
{
var inputQueue = new BlockingCollection();
foreach (var id in documentIds)
inputQueue.Add(id);
inputQueue.CompleteAdding();
return inputQueue;
}
در این مثال، ابتدا GetDocumentIdsToProcess را برای دریافت لیست id اسنادی که باید پردازش شوند فراخوانی میکنیم. سپس تمام idها را با متد CreateInputQueue به شیء جدید BlockingCollection (در متغیر inputQueue) اضافه میکنیم. در حال حاضر، از عمل استفاده از BlockingCollection برای ذخیره id اسناد چشمپوشی میکنیم. ما در اینجا فقط از آن به عنوان یک مجموعه thread-safe با API مناسب استفاده کردهایم. بعدا در مورد آن توضیح خواهیم داد.
سپس یک شیء BlockingCollection ایجاد میکنیم که حداکثر اندازه صف را با 500 آیتم مشخص میکند. این شیء به عنوان صف بین تولیدکننده و مصرفکننده قرار میگیرد. داشتن محدودیت روی اندازه صف سبب میشود که تولیدکننده را وقتی که صف پر است و سعی میکند آیتم اضافه کند، مسدود کند.
سپس وظیفهای (task) را (از طریق Task.Run) برای مصرف اسناد از صف ایجاد میکنیم.
از متد GetConsumingEnumerable برای گرفتن یک IEnumerable استفاده میکنیم که میتواند برای حلقه زدن روی اسناد تولیدشده، به محض اینکه قابل دسترس شدند، مورد استفاده قرار گیرد. اگر صف خالی باشد، فراخوانی IEnumerable.MoveNext مسدود میشود تا حلقه را متوقف کند. در بدنه حلقه، SaveDocumentToDestinationStore را برای ذخیرهسازی اسناد ترجمه شده فراخوانی میکنیم.
سپس، هفت task ایجاد میکنیم تا اسناد ترجمه شده را تولید کند.
هر تولیدکننده GetConsumingEnumerable را بر روی BlockingCollection شناسههای اسناد (در متغیر inputQueue) برای دریافت تعدادی از idهای اسناد برای پردازش فراخوانی میکند. برای هر id سند، یک تولیدکننده یک ترجمه سند را میخواند و سپس از طریق متد Add آن را به سند اضافه میکند.
توجه داشته باشید که کلاس BlockingCollection آیتمهای خوانده شده چندین thread را به صورت صحیح مدیریت میکند، به این ترتیب هیچ آیتمی توسط دو thread خوانده نمیشود.
شاید تعجب کنید که چرا یک BlockingCollection برای صف ورودی داریم. همان طور که گفتم این کار ساده و مناسب است. هنگام ذخیرهسازی شناسههای سند در یک آرایه یا لیست، باید خودمان نحوه تخصیص صحیح دادهها به thread تولیدکننده را مدیریت کنیم.
سپس، برای تمام taskهای تولید شده منتظر میمانیم تا از طریق متد Task.WaitAll تکمیل شوند. سپس متد CompleteAdding را فراخوانی میکنیم تا مجموعههای تکمیلشده را علامتگذاری کند.
وقتی این اتفاق میافتد، حلقه مصرفکننده (حلقه foreach) زمانی که تمام آیتمها پردازش میشوند، تکمیل خواهد شد. در جزئیات بیشتر، وقتی صف خالی میشود، IEnumerable بازگشتی از GetConsumingEnumerable خاتمه خواهد یافت (IEnumerable.MoveNext مقدار false را برمیگرداند). بدون فراخوانی CompleteAdding، IEnumerable.MoveNext به سادگی مسدود میشود تا برای افزودن سند جدید به صف منتظر بماند.
درنهایت، برای تکمیل کار مصرفکننده منتظر می مانیم تا مطمئن شویم که متد ProcessDocumentsUsingProducerConsumerPattern قبل از اینکه همه اسناد به طور کامل پردازش شوند، باز نمیگردد.
توجه داشته باشید که این فقط یک سناریو است که میتوانیم از الگوی تولیدکننده-مصرف کننده استفاده کنیم.
در سناریوهای دیگر، ممکن است مجموعهای از اسناد با سایز ثابت که باید پردازش شوند را نداشته باشیم، بنابراین منطقی نیست که صبر کنیم تا تولیدکننده یا مصرفکننده به پایان برسند.
مثلا ممکن است بخواهیم یک پردازش بیپایان از خواندن اسناد جدید از صف MSMQ و پردازش آنها داشته باشیم.
الگوی خط لوله (pipeline)
در مثال ما، تصور کنید که هر مرحله از پردازش اسناد دارای مرحله ای از نیازهای موازیسازی باشد که زمان اجرای آن غالبا تغییر میکند. در این مورد باید دو صف ایجاد شود، یکی برای خواندن اسناد و دیگری برای ترجمه اسناد.
شکل زیر این مورد را نشان می دهد:
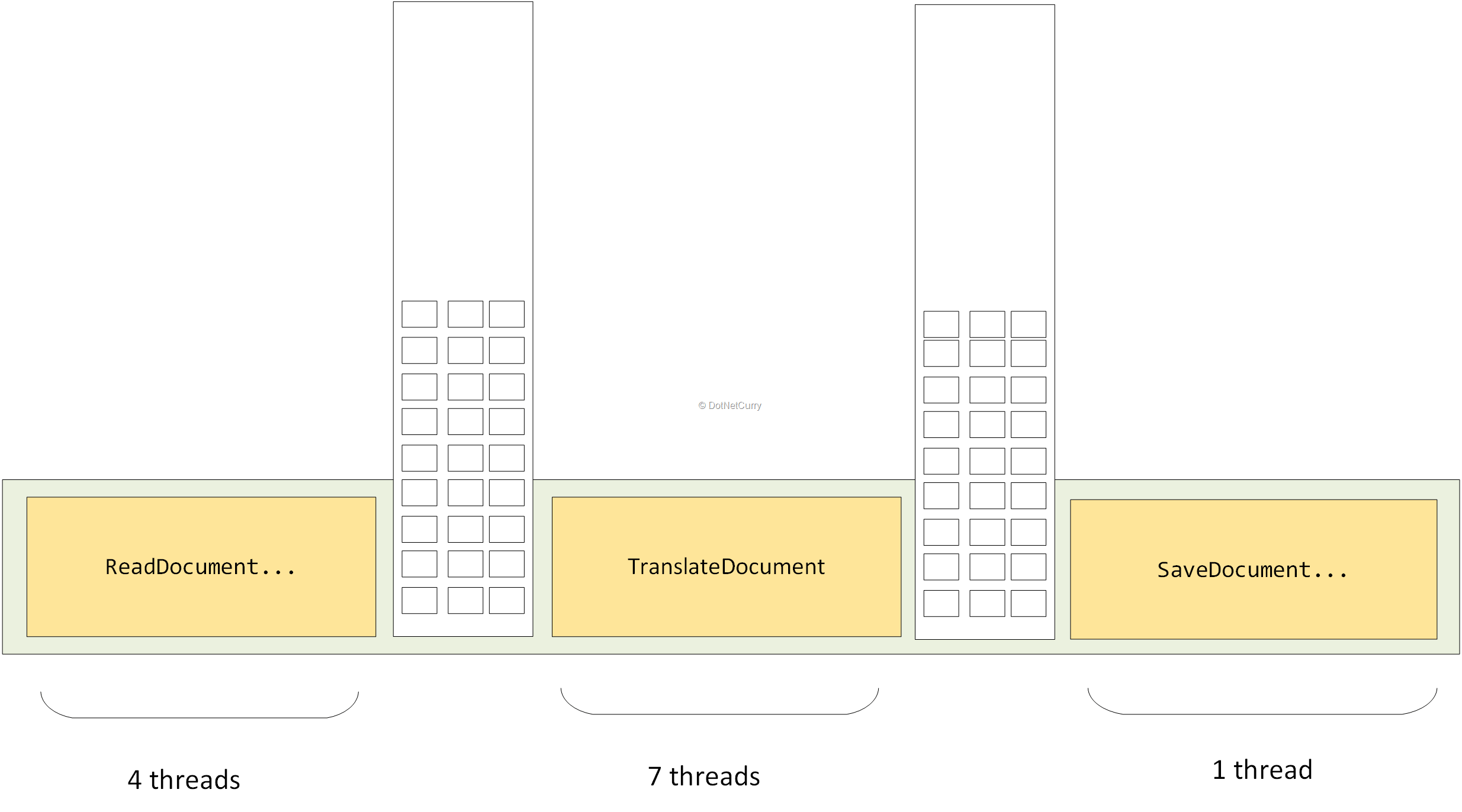
اساسا الگوی pipeline نوع دیگری از الگوی تولیدکننده-مصرفکننده است.
در این الگو، برخی از مصرفکنندگان نیز تولید میکنند.
در این مثال خاص، فرآیند ترجمه هم مصرفکننده و هم تولیدکننده است. اسناد را از صف اول میگیرد، آنها را ترجمه کرده، سپس به صف دوم اضافه میکند.
میتوانیم این الگو را به راحتی با استفاده از دو شیء BlockingCollection پیادهسازی کنیم ( و همانطور که در مثال قبل توضیح داده شد، از BlockingCollection دیگری برای نگه داشتن id های اسناد ورودی برای راحتی کار استفاده کنیم):
public void ProcessDocumentsUsingPipelinePattern()
{
string[] documentIds = GetDocumentIdsToProcess();
BlockingCollection inputQueue = CreateInputQueue(documentIds);
BlockingCollection queue1 = new BlockingCollection(500);
BlockingCollection queue2 = new BlockingCollection(500);
var savingTask = Task.Run(() =>
{
foreach (var translatedDocument in queue2.GetConsumingEnumerable())
{
SaveDocumentToDestinationStore(translatedDocument);
}
});
var translationTasks =
Enumerable.Range(0, 7)
.Select(_ =>
Task.Run(() =>
{
foreach (var readDocument in queue1.GetConsumingEnumerable())
{
var translatedDocument =
TranslateDocument(readDocument, Language.English);
queue2.Add(translatedDocument);
}
}))
.ToArray();
var readingTasks =
Enumerable.Range(0, 4)
.Select(_ =>
Task.Run(() =>
{
foreach (var documentId in inputQueue.GetConsumingEnumerable())
{
var document = ReadDocumentFromSourceStore(documentId);
queue1.Add(document);
}
}))
.ToArray();
Task.WaitAll(readingTasks);
queue1.CompleteAdding();
Task.WaitAll(translationTasks);
queue2.CompleteAdding();
savingTask.Wait();
}
نکاتی در مورد عملیات I/O و برنامههای سرور
عملیات خواندن و ذخیرهسازی در مثال ما، عملیات I/O هستند. اگر به طور همزمان عملیات I/O را فراخوانی کنیم، مثلا با استفاده از File.ReadAllBytes، در حالی که عملیات در حال اجراست، thread فراخوانی مسدود خواهد شد.
وقتی یک thread مسدود میشود، چرخه CPU مصرف نمیکند. و در برنامههای دسکتاپ، داشتن تعداد کمی thread که روی I/O مسدود میشود مسألهای نیست.
اما در برنامههای سرور، مثلا برنامههای WCF، داستان فرق میکند!
اگر ما صدها درخواست همزمان داشته باشیم که برای پردازش نیاز به دسترسی برخی از I/Oها داشته باشند، اگر در I/O مسدود نشویم بهتر است. دلیل این امر این است که I/O نیازی به thread ندارد و به جای انتظار، thread می تواند برود و درخواست دیگری را پردازش کند، بنابراین توان عملیاتی افزایش پیدا میکند.
در تمام مثالهایی که زدیم، تمام عملیات I/O به صورت همزمان انجام میشوند، بنابراین آنها برای برنامههای سرور که نیاز به توان عملیاتی بالا دارند مناسب نیستند.
همچنین وقتی لازم است برای صف تولیدکننده-مصرفکننده برای خالی نبودن (در سمت مصرفکننده) و پر نبودن (در سمت تولیدکننده) منتظر بمانیم، منطقی نیست که thread جاری مسدود شود.
کتابخانه TPL Dataflow میتواند برای پیادهسازی الگوهای تولیدکننده-مصرف کننده و pipeline مورد استفاده قرار گیرد. این کتابخانه پشتیبانی خوبی برای عملیات غیرهمزمان دارد و می تواند برای سناریوهای سرور استفاده شود.
الگوی Dataflow
کتابخانه TPL Dataflow که در بالا ذکر شد، از یکی دیگر از الگوهای تولیدکننده-مصرفکننده به نام Dataflow پشتیبانی میکند.
الگوی Dataflow نسبت به الگوی pipeline متفاوت است، زیرا جریان دادهها خطی نیستند. به عنوان مثال، میتوانید اسناد را با توجه به شرایطشان به صفهای مختلف ببرید. یا میتوانید یک سند را به دو صف بفرستید تا آنها را به دو زبان انگلیسی و اسپانیایی ترجمه کنید.
نتیجهگیری
در این مقاله، در مورد الگوی تولیدکننده-مصرف کننده و یک نوع از این الگو صحبت کردیم؛ الگوی pipeline.
در مورد اینکه چرا این الگوها به جای موازیسازی استفاده میشوند نیز بحث کردیم. یکی از دلایل استفاده این الگوها این بود که آنها کنترل بیشتری روی مراحل موازیسازی که هر مرحله از پردازش دارد را به ما می دهند. همچنین وقتی زمان اجرای برخی عملیاتها تغییر میکند، توان عملیاتی را بالا میبرد.
همچنین مثالهایی در مورد نحوه پیادهسازی این الگوها با استفاده از کلاس BlockingCollection در .NET ارائه دادیم.

- C#.net
- 3k بازدید
- 4 تشکر