بهینه سازی کوئریهای LINQ در C#.NET برای MS SQL Server
شنبه 5 مهر 1399LINQ به عنوان یک زبان قدرتمند برای مدیریت اطلاعات به .NET اضافه شد. به عنوان مثال LINQ to SQL با استفاده ازEntity Framework به شما این امکان را می دهد با DBMS به سهولت صحبت کنید. اما اغلب هنگام استفاده از آن، توسعهدهندگان فراموش میکنند که بررسی کنند چه نوع query SQl ای توسط provider ای که قابلیت کوئری زدن دارد، تولید میشود (در مثال ما Entity Framework). در این مقاله ما بررسی خواهیم کرد که چگونه میتوانیم عملکرد کوئریهای LINQ را بهینه کنیم.

پیاده سازی
بیایید با استفاده از یک مثال دونکته مهم را بررسی کنیم.
ابتدا باید پایگاه داده Test را در SQL Server ایجاد کنیم. در این دیتابیس با اجرای کوئری زیر دو جدول ایجاد خواهیم شد.
USE [TEST]
GO
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE TABLE [dbo].[Ref](
[ID] [int] NOT NULL,
[ID2] [int] NOT NULL,
[Name] [nvarchar](255) NOT NULL,
[InsertUTCDate] [datetime] NOT NULL,
CONSTRAINT [PK_Ref] PRIMARY KEY CLUSTERED
(
[ID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO
ALTER TABLE [dbo].[Ref] ADD CONSTRAINT [DF_Ref_InsertUTCDate] DEFAULT (getutcdate()) FOR [InsertUTCDate]
GO
USE [TEST]
GO
SET ANSI_NULLS ON
GO
SET QUOTED_IDENTIFIER ON
GO
CREATE TABLE [dbo].[Customer](
[ID] [int] NOT NULL,
[Name] [nvarchar](255) NOT NULL,
[Ref_ID] [int] NOT NULL,
[InsertUTCDate] [datetime] NOT NULL,
[Ref_ID2] [int] NOT NULL,
CONSTRAINT [PK_Customer] PRIMARY KEY CLUSTERED
(
[ID] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO
ALTER TABLE [dbo].[Customer] ADD CONSTRAINT [DF_Customer_Ref_ID] DEFAULT ((0)) FOR [Ref_ID]
GO
ALTER TABLE [dbo].[Customer] ADD CONSTRAINT [DF_Customer_InsertUTCDate] DEFAULT (getutcdate()) FOR [InsertUTCDate]
GO
حالا جدول Ref را به کمک script زیر پرمی کنیم. صبر کنید... ما فقط یک script را اجرا کردیم اما آن را ذخیره نکردیم. در چنین مواردی، SQL Complete به کمک Devart بسیار راحت خواهد بود، که با SSMS و Visual Studio ادغام می شود و دارای ویژگی Execution History است.
این عملکرد تاریخچه اجرا شده کوئری ها در SSMS را نمایش می دهد.
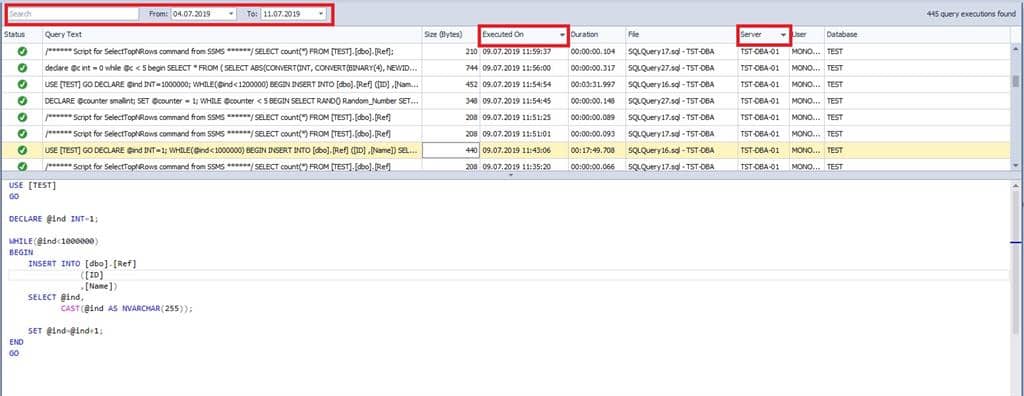
توجه کنید پنجره از عناصر زیر تشکیل شده است :
1. باکس جستجو برای فیلتر کردن نتایج
2. باکس دامنه تاریخ برای فیلتر کردن نتایج
3. نتایج ارائه شده در یک جدول. می توانید داده ها را بر اساس ستون های این جدول مرتب کنید (با استفاده از کلید SHIFT می توانید مجموعه ای از ستون ها را برای مرتب سازی انتخاب کنید)
4. کد ردیف انتخاب شده
جدول نتیجه حاوی تاریخچه اسکریپت های اجرا شده در SSMS است و جداول زیر را شامل می شود:
Status .1: نشان می دهد که اسکریپت با موفقیت اجرا شده یا خیر
Query Text .2: کد اسکریپت
Size (Bytes) .3: اندازه متن در واحد بایت
Executed On .4: تاریخ و ساعت اسکریپت اجرا شده
Duration .5: مدت زمان اجرای اسکریپت
File .6: نام یک فایل یا زبانه در SSMS و همراه با نام نمونه SQL Server که اسکریپت روی آن اجرا شده است
Server .7: نام نمونه SQL Server که اسکریپت روی آن اجرا شده است
User .8: ورود به سیستم تحت اسکریپت اجرا شده
Database .9: بستر پایگاه داده ای که اسکریپت در آن اجرا شده است
ما می توانیم کوئری مورد نیاز را در این جدول پیدا کنیم،
USE [TEST]
GO
DECLARE @ind INT=1;
WHILE(@ind<1200000)
BEGIN
INSERT INTO [dbo].[Ref]
([ID]
,[ID2]
,[Name])
SELECT
@ind
,@ind
,CAST(@ind AS NVARCHAR(255));
SET @ind=@ind+1;
END
GO
به روشی مشابه، می توانیم جدول مشتری را با استفاده از اسکریپت زیر پر کنیم
USE [TEST]
GO
DECLARE @ind INT=1;
DECLARE @ind_ref INT=1;
WHILE(@ind<=12000000)
BEGIN
IF(@ind%3=0) SET @ind_ref=1;
ELSE IF (@ind%5=0) SET @ind_ref=2;
ELSE IF (@ind%7=0) SET @ind_ref=3;
ELSE IF (@ind%11=0) SET @ind_ref=4;
ELSE IF (@ind%13=0) SET @ind_ref=5;
ELSE IF (@ind%17=0) SET @ind_ref=6;
ELSE IF (@ind%19=0) SET @ind_ref=7;
ELSE IF (@ind%23=0) SET @ind_ref=8;
ELSE IF (@ind%29=0) SET @ind_ref=9;
ELSE IF (@ind%31=0) SET @ind_ref=10;
ELSE IF (@ind%37=0) SET @ind_ref=11;
ELSE SET @ind_ref=@ind%1190000;
INSERT INTO [dbo].[Customer]
([ID]
,[Name]
,[Ref_ID]
,[Ref_ID2])
SELECT
@ind,
CAST(@ind AS NVARCHAR(255)),
@ind_ref,
@ind_ref;
SET @ind=@ind+1;
END
GO
ابزار SQL Complete در حفظ قالب منظم کد اسکریپت ها به شما می تواند کمک کند.
به این ترتیب ، ما دو جدول ایجاد کردیم - یکی از آنها بیش از 1 میلیون ردیف دارد و دیگری بیش از 10 میلیون ردیف دارد.
اکنون باید یک پروژه آزمایشی در Visual C# Console App ایجاد کنیم:
در قدم بعدی ، باید یک کتابخانه به Entity Framework اضافه کنیم تا بتوانیم با پایگاه داده در ارتباط باشیم.
برای افزودن این کتابخانه، روی پروژه کلیک راست کنید و‘Manage NuGet Packages …’ را در منو انتخاب کنید،
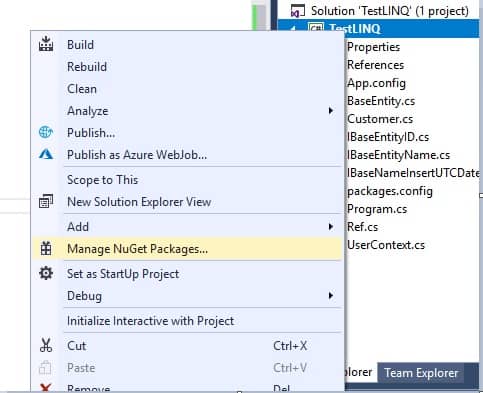
در پنجره باز شده، "Entity Framework" را در کادر جستجو وارد کنید، بسته Entity Framework را انتخاب کنید و آن را نصب کنید:

در قدم بعد، در فایل App.config، کدهای زیر را بعد ازعنصر configSections اضافه می کنیم:
<connectionStrings>
<add name="DBConnection" connectionString="data source=MSSQL_INSTANCE_NAME;Initial Catalog=TEST;Integrated Security=True;" providerName="System.Data.SqlClient" />
</connectionStrings>
مطمئن شوید رشته اتصال در connection string وارد شده باشد.
حالا سه Interface در فایل های جداگانه ایجاد می کنیم:
IBaseEntityID
namespace TestLINQ
{
public interface IBaseEntityID
{
int ID { get; set; }
}
}
IBaseEntityName
namespace TestLINQ
{
public interface IBaseEntityName
{
string Name { get; set; }
}
}
IBaseNameInsertUTCDate
namespace TestLINQ
{
public interface IBaseNameInsertUTCDate
{
DateTime InsertUTCDate { get; set; }
}
}
در یک فایل جداگانه، یک کلاس BaseEntity برای دو موجودیت خود ایجاد می کنیم که شامل فیلدهای مشترک آنها باشد.
namespace TestLINQ
{
public class BaseEntity : IBaseEntityID, IBaseEntityName, IBaseNameInsertUTCDate
{
public int ID { get; set; }
public string Name { get; set; }
public DateTime InsertUTCDate { get; set; }
}
}
در قدم بعد دو موجودیت (Entitie) می سازیم هر کدام در فایل جداگانه:
Ref
using System.ComponentModel.DataAnnotations.Schema;
namespace TestLINQ
{
[Table("Ref")]
public class Ref : BaseEntity
{
public int ID2 { get; set; }
}
}
Customer
using System.ComponentModel.DataAnnotations.Schema;
namespace TestLINQ
{
[Table("Customer")]
public class Customer: BaseEntity
{
public int Ref_ID { get; set; }
public int Ref_ID2 { get; set; }
}
}
در آخر یک UserContext در یک فایل جداگانه ایجاد می کنیم،
using System.Data.Entity;
namespace TestLINQ
{
public class UserContext : DbContext
{
public UserContext()
: base("DbConnection")
{
Database.SetInitializer<UserContext>(null);
}
public DbSet<Customer> Customer { get; set; }
public DbSet<Ref> Ref { get; set; }
}
}
به این ترتیب، ما یک راهکار برای انجام تست های بهینه سازی به کمک LINQ to SQL از طریق Entity Framework برای MS SQL Server دریافت می کنیم:
اکنون، کد زیر را در Program.cs وارد می کنیم:
using System;
using System.Collections.Generic;
using System.Linq;
namespace TestLINQ
{
class Program
{
static void Main(string[] args)
{
using (UserContext db = new UserContext())
{
var dblog = new List<string>();
db.Database.Log = dblog.Add;
var query = from e1 in db.Customer
from e2 in db.Ref
where (e1.Ref_ID == e2.ID)
&& (e1.Ref_ID2 == e2.ID2)
select new { Data1 = e1.Name, Data2 = e2.Name };
var result = query.Take(1000).ToList();
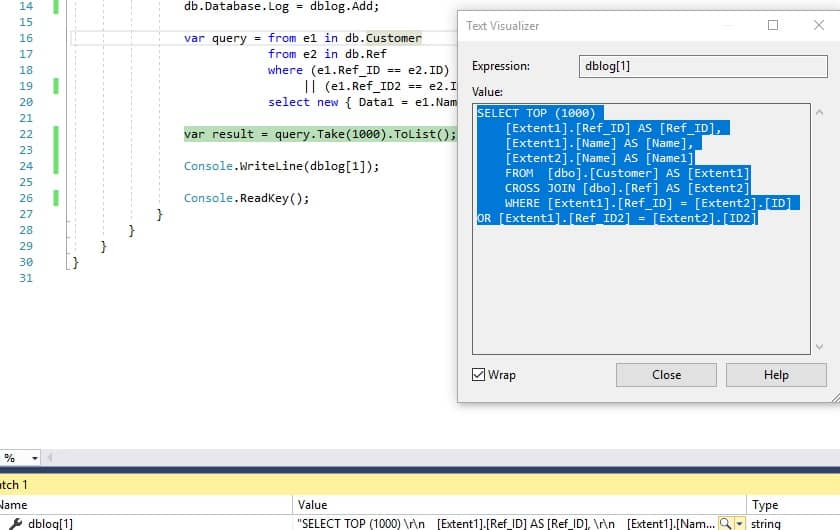
Console.WriteLine(dblog[1]);
Console.ReadKey();
}
}
}
}
وقتی پروژه را اجرا کنیم، این خروجی است که به عنوان نتیجه در کنسول خواهیم دید،
SELECT TOP (1000)
[Extent1].[Ref_ID] AS [Ref_ID],
[Extent1].[Name] AS [Name],
[Extent2].[Name] AS [Name1]
FROM [dbo].[Customer] AS [Extent1]
INNER JOIN [dbo].[Ref] AS [Extent2] ON ([Extent1].[Ref_ID] = [Extent2].[ID]) AND ([Extent1].[Ref_ID2] = [Extent2].[ID2])
همانطور که مشاهده می کنید، یک LINQ query به طور کارآمد SQL query را در
MS SQL Server DBMS ایجاد کرده است.
حالا، شرط AND را به OR در LINQ query تغییر می دهیم
var query = from e1 in db.Customer
from e2 in db.Ref
where (e1.Ref_ID == e2.ID)
|| (e1.Ref_ID2 == e2.ID2)
select new { Data1 = e1.Name, Data2 = e2.Name };
دوباره برنامه را اجرا می کنیم
یک خطا رخ میدهد، از شرح خطا، متوجه می شویم که عملیات پس از 30 ثانیه به پایان رسیده است،
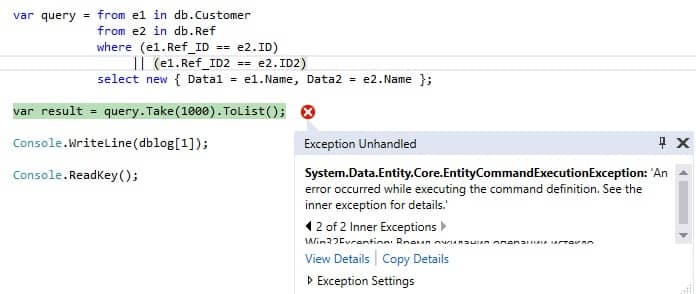
این کوئریی است که LINQ ایجاد کرده است:
می بینیم که گزینش از یک حاصلضرب دکارتی از دو مجموعه (جدول) انجام می شود
SELECT TOP (1000)
[Extent1].[Ref_ID] AS [Ref_ID],
[Extent1].[Name] AS [Name],
[Extent2].[Name] AS [Name1]
FROM [dbo].[Customer] AS [Extent1]
CROSS JOIN [dbo].[Ref] AS [Extent2]
WHERE [Extent1].[Ref_ID] = [Extent2].[ID] OR [Extent1].[Ref_ID2] = [Extent2].[ID2]
LINQ query را دوباره به این صورت می نویسیم
var query = (from e1 in db.Customer
join e2 in db.Ref
on e1.Ref_ID equals e2.ID
select new { Data1 = e1.Name, Data2 = e2.Name }).Union(from e1 in db.Customer
join e2 in db.Ref
on e1.Ref_ID2 equals e2.ID2
se
این SQL query هست که به عنوان نتیجه دریافت می کنیم
SELECT
[Limit1].[C1] AS [C1],
[Limit1].[C2] AS [C2],
[Limit1].[C3] AS [C3]
FROM ( SELECT DISTINCT TOP (1000)
[UnionAll1].[C1] AS [C1],
[UnionAll1].[Name] AS [C2],
[UnionAll1].[Name1] AS [C3]
FROM (SELECT
1 AS [C1],
[Extent1].[Name] AS [Name],
[Extent2].[Name] AS [Name1]
FROM [dbo].[Customer] AS [Extent1]
INNER JOIN [dbo].[Ref] AS [Extent2] ON [Extent1].[Ref_ID] = [Extent2].[ID]
UNION ALL
SELECT
1 AS [C1],
[Extent3].[Name] AS [Name],
[Extent4].[Name] AS [Name1]
FROM [dbo].[Customer] AS [Extent3]
INNER JOIN [dbo].[Ref] AS [Extent4] ON [Extent3].[Ref_ID2] = [Extent4].[ID2]) AS [UnionAll1]
) AS [Limit1]
متأسفانه ، فقط یک شرط اتصال در یک LINQ query وجود دارد، بنابراین می توانیم با ایجاد یک کوئری برای هر دو شرط و سپس ترکیب آنها با استفاده از Union برای حذف خطوط تکراری ، به نتایج دلخواه برسیم.
بله، با توجه به اینکه تمام ردیف های تکراری را می توانید برگردانید کوئری ها در اکثر موارد نابرابر خواهند بود. با این حال ، در زندگی واقعی به ردیف های تکراری نیازی نیست و معمولاً مواردی هستند که می خواهید از آنها خلاص شوید.
حال بیایید برنامه های اجرایی این دو کوئری را با هم مقایسه کنیم:
میانگین زمان اجرا برای ,CROSS JOIN 195 ثانیه است
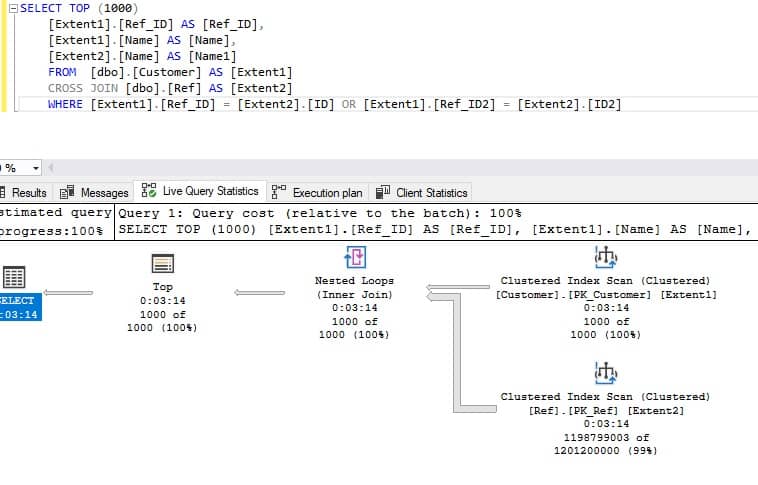
میانگین زمان اجرا برای INNER JOIN-UNION کمتر از 24 ثانیه است
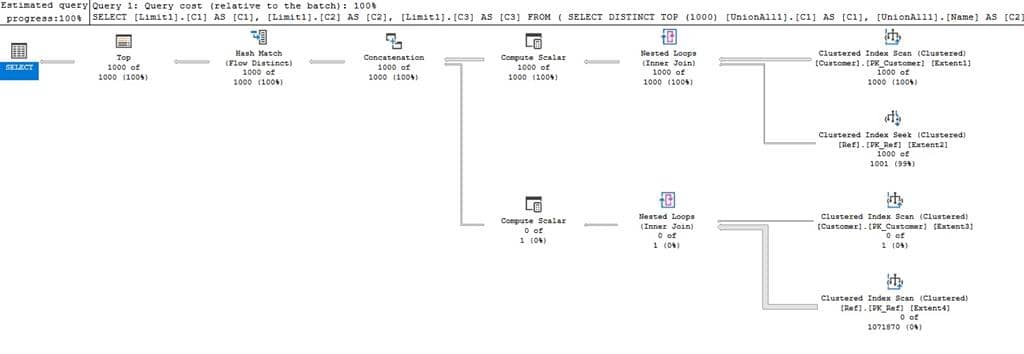
همانطور که از نتایج مشاهده می کنیم، LINQ query بهینه شده چندین برابر سریعتر از یک مورد بهینه نشده در این دو جدول با میلیون ها رکورد، کار می کند.
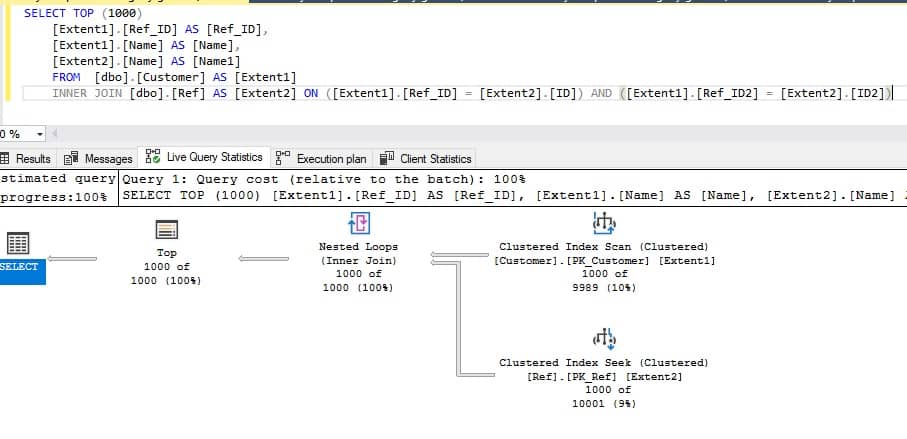
برای ورژن با شرط AND، یک LINQ query به این شکل خواهد بود،
var query = from e1 in db.Customer
from e2 in db.Ref
where (e1.Ref_ID == e2.ID)
&& (e1.Ref_ID2 == e2.ID2)
select new { Data1 = e1.Name, Data2 = e2.Name };
تقریباً در این حالت ، یک SQL query صحیح ایجاد می شود ، با زمان اجرای تقریباً 24 ثانیه:
همچنین، برای عملیات LINQ to Objects، به جای کوئری که به این شکل است:
var query = from e1 in seq1
from e2 in seq2
where (e1.Key1==e2.Key1)
&& (e1.Key2==e2.Key2)
select new { Data1 = e1.Data, Data2 = e2.Data };
می توانیم از کوئری مشابه زیر استفاده کنیم:
var query = from e1 in seq1
join e2 in seq2
on new { e1.Key1, e1.Key2 } equals new { e2.Key1, e2.Key2 }
select new { Data1 = e1.Data, Data2 = e2.Data };
جایی که
Para[] seq1 = new[] { new Para { Key1 = 1, Key2 = 2, Data = "777" }, new Para { Key1 = 2, Key2 = 3, Data = "888" }, new Para { Key1 = 3, Key2 = 4, Data = "999" } };
Para[] seq2 = new[] { new Para { Key1 = 1, Key2 = 2, Data = "777" }, new Para { Key1 = 2, Key2 = 3, Data = "888" }, new Para { Key1 = 3, Key2 = 5, Data = "999" } };
نوع Para به روش زیر تعریف می شود:
class Para
{
public int Key1, Key2;
public string Data;
}
نتیجه گیری
ما برخی از حالت های بهینه سازی LINQ query را برای MS SQL Server بررسی کردیم. همچنین، SQL Complete در جستجوی تاریخچه کوئری و همچنین قالب بندی اسکریپت هایی که در این مقاله استفاده کردیم، به ما کمک زیادی کرد.
متأسفانه، حتی توسعه دهندگان با تجربه .NET نیز اغلب فراموش می کنند که درک دستورالعمل های استفاده شده در پس زمینه ضروری است. وگرنه، آنها می توانند پیکربندی شده و در آینده بمب ساعتی مجازی تنظیم کنند، چه زمانی که راه حل مقیاس بندی شده باشد و چه زمانی که عوامل خارجی کمی تغییر کند.
همچنین ، پوشه Plans از این ریپازیتوری شامل برنامه های اجرایی کوئری ها با شرط OR است.
علاوه بر این ، یک راه حل خوب به نام dotConnect وجود دارد، که یک سطر از کامپوننت های data access از Devart برای DBMS های متنوع است. از میان آنها، مولفه های dotConnect از ابزارهای ORM مانند Entity Framework Core و LinqConnect پشتیبانی می کنند که به شما این امکان را می دهد با کلاس های LINQ to SQL کار کنید.

- SQL Server
- 3k بازدید
- 1 تشکر